Rules to Better Code
Do you refactor your code and keep methods short?
Refactoring is all about making code easier to understand and cheaper to modify without changing its behavior.
As a rule of thumb, no method should be greater than 50 lines of code. Long-winded methods are the bane of any developer and should be avoided at all costs. Instead, a method of 50 lines or more should be broken down into smaller functions.
Do you know when functions are too complicated?
You should generally be looking for ways to simplify your code (e.g. removing heavily-nested case statements). As a minimum, look for the most complicated method you have and check whether it needs simplifying.
In Visual Studio, there is built-in support for Cyclomatic Complexity analysis.
- Go to Analyze | Calculate Code Metrics | For Solution
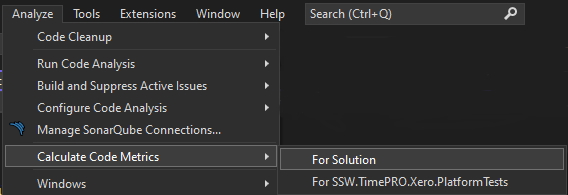
Figure: Launching the Code Metrics tool within Visual Studio
- Look at the function with the largest Cyclomatic Complexity number and consider refactoring to make it simpler.

Figure: Results from cyclomatic analysis (and other analyses) give an indication of how complicated functions are
Tip: Aim for "green" against each function's Maintainability Index.
Do you use AI pair programming?
Too often, developers are writing a line of code, and they forget that little bit of syntax they need to do what they want. In that case, they usually end up googling it to find the documentation and then copy and paste it into their code. That process is a pain because it wastes valuable dev time. They might also ask another dev for help.
Not to worry, AI pair programming is here to save the day!
Video: 6 ways GitHub Copilot helps you write better code faster (7 min)Video: Say hello to GitHub Copilot Enterprise! (17 min)New tools like GitHub Copilot provide devs with potentially complete solutions as they type. It might sound like it's too good to be true, but in reality you can do so much with these tools.
"It’s hard to believe that GitHub Copilot is actually an AI and not a Mechanical Turk. The quality of the code is at the very least comparable to my own (and in fairness that's me bragging), and it's staggering to see how accurate it is in determining your needs, even in the most obscure scenarios." - Matt Goldman
What can it do?
There is a lot to love with AI pair programming ❤️, here is just a taste of what it can do:
Help with writing code
- Populate a form
- Do complex maths
- Create DTOs
- Hydrate data
- Query APIs
- Do unit tests
GitHub Copilot - Help with reading and understanding code
- Generate Pull Request summaries
- Explore and learn about a codebase
- Understand PBIs and how to implement them
Some tools that offer this are GitHub Copilot or Codeium (not to be confused with Codium).
Why is it awesome?
AI pair programming has so much to offer, here are the key benefits:
- Efficiency - Less time doing gruntwork like repetitive tasks and making boilerplate
- Learnability - Quick suggestions in heaps of languages, such as:
- C#
- JavaScript
- SQL, and many more
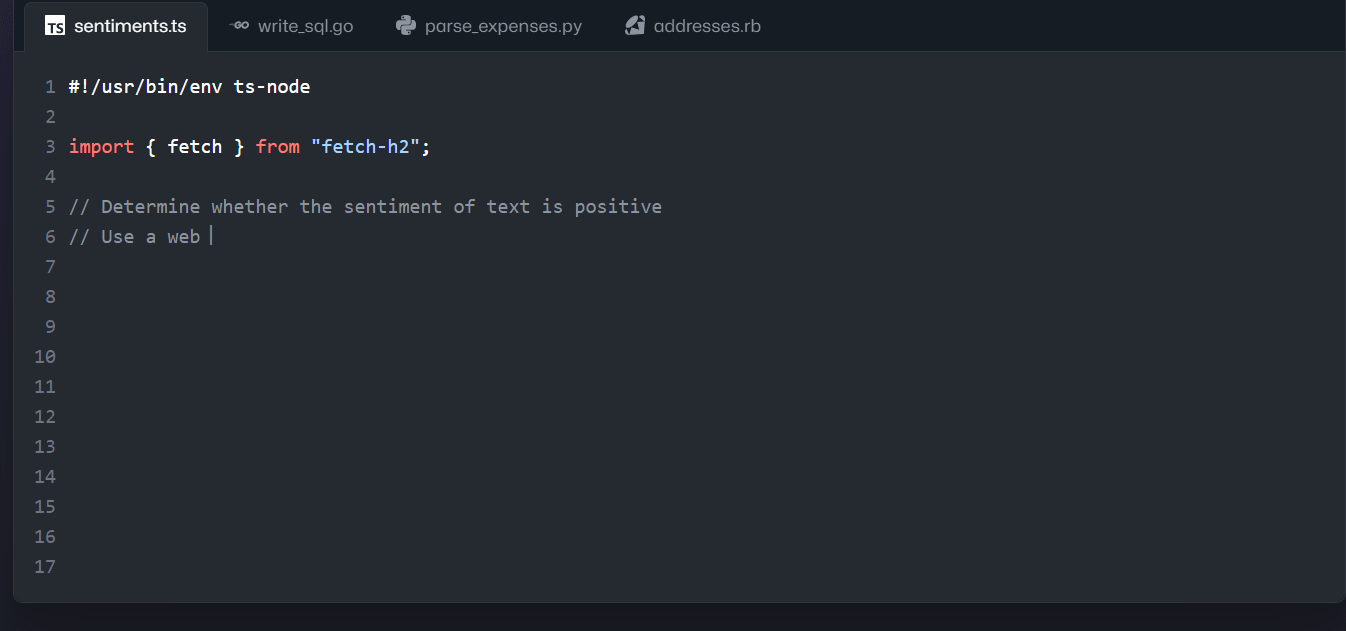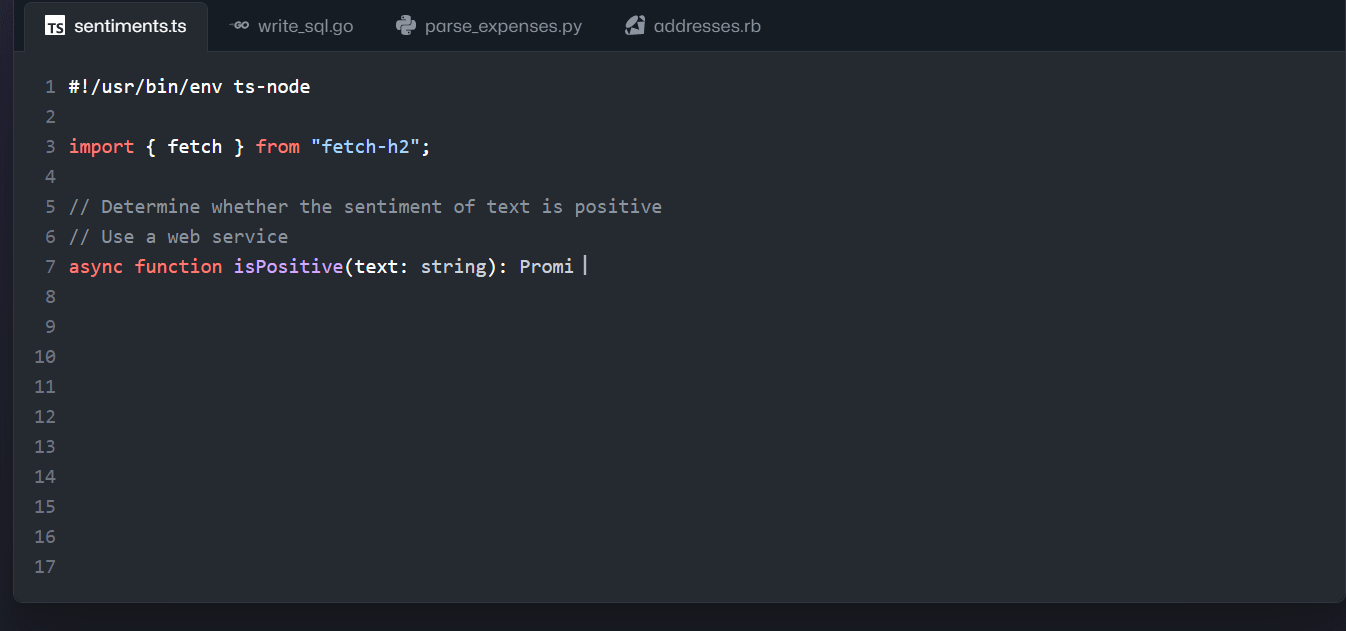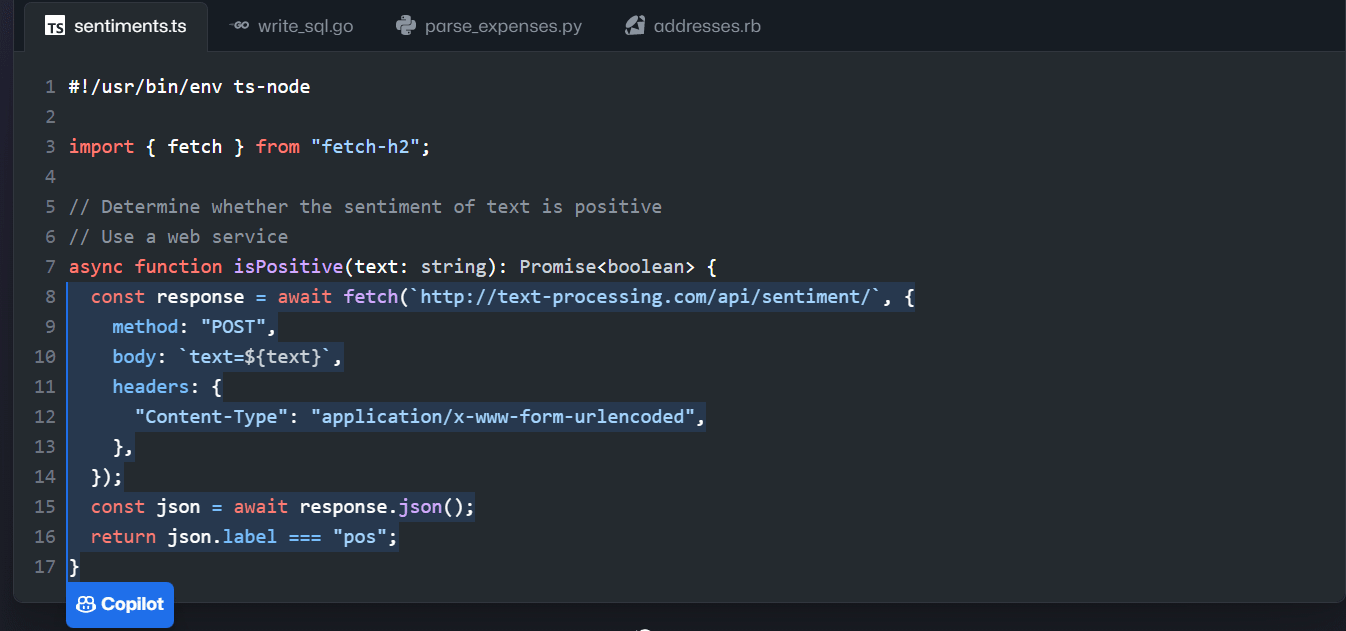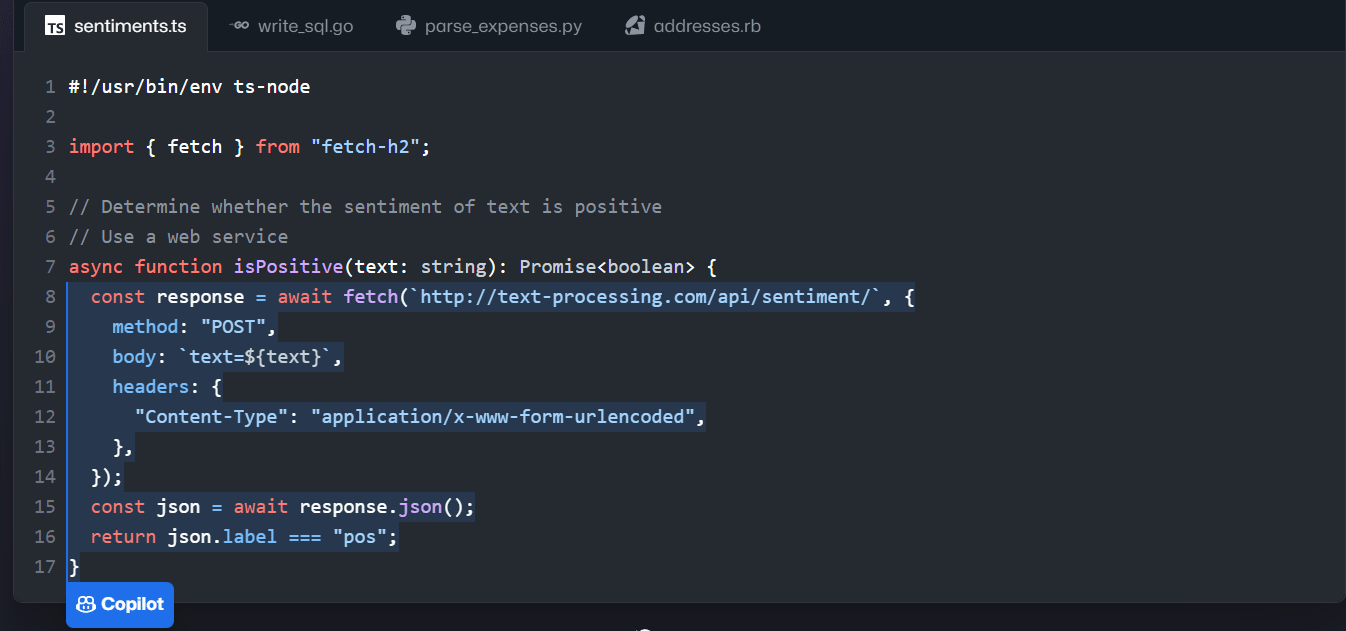
✅ Figure: Good example - GitHub Copilot saves you oodles of time!
Do you look for duplicate code?
Code duplication is a big "code smell" that harms maintainability. You should keep an eye out for repeated code and make sure you refactor it into a single place.
For example, have a look at these two Action methods in an MVC 4 controller.
//// GET: /Person/[Authorize]public ActionResult Index(){// get company this user can viewCompany company = null;var currentUser = Session["CurrentUser"] as User;if (currentUser != null){company = currentUser.Company;}// show people in that companyif (company != null){var people = db.People.Where(p => p.Company == company);return View(people);}else{return View(new List());}}//// GET: /Person/Details/5[Authorize]public ActionResult Details(int id = 0){// get company this user can viewCompany company = null;var currentUser = Session["CurrentUser"] as User;if (currentUser != null){company = currentUser.Company;}// get matching personPerson person = db.People.Find(id);if (person == null || person.Company == company){return HttpNotFound();}return View(person);}❌ Figure: Figure: Bad Example - The highlighted code is repeated and represents a potential maintenance issue.
We can refactor this code to make sure the repeated lines are only in one place.
private Company GetCurrentUserCompany(){// get company this user can viewCompany company = null;var currentUser = Session["CurrentUser"] as User;if (currentUser != null){company = currentUser.Company;}return company;}//// GET: /Person/[Authorize]public ActionResult Index(){// get company this user can viewCompany company = GetCurrentUserCompany();// show people in that companyif (company != null){var people = db.People.Where(p => p.Company == company);return View(people);}else{return View(new List());}}// GET: /Person/Details/5[Authorize]public ActionResult Details(int id = 0){// get company this user can viewCompany company = GetCurrentUserCompany();// get matching personPerson person = db.People.Find(id);if (person == null || person.Company == company){return HttpNotFound();}return View(person);}✅ Figure: Figure: Good Example - The repeated code has been refactored into its own method.
Tip: The Refactor menu in Visual Studio 11 can do this refactoring for you.
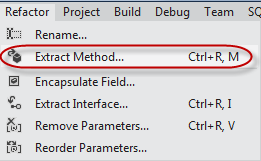
Figure: The Extract Method function in Visual Studio's Refactor menu
Do you maintain separation of concerns?
One of the major issues people had back in the day with ASP (before ASP.NET) was the prevalence of "Spaghetti Code". This mixed Reponse.Write() with actual code.
Ideally, you should keep design and code separate - otherwise, it will be difficult to maintain your application. Try to move all data access and business logic code into separate modules.
Bob Martin explains this best:
Do you follow naming conventions?
It's the most obvious - but naming conventions are so crucial to simpler code, it's crazy that people are so loose with them...
For Javascript / Typescript
Google publishes a JavaScript style guide. For more guides, please refer to this link: Google JavaScript Style Guide
Here are some key points:
- Use const or let – Not var
- Use semicolons
- Use arrow functions
- Use template strings
- Use uppercase constants
- Use single quotes
See 13 Noteworthy Points from Google’s JavaScript Style Guide
For C# Java
See chapter 2: Meaningful Names Clean Code: A Handbook of Agile Software Craftsmanship
For SQL (see Rules to Better SQL Databases)
Do you use the testing stage, in the file name?
When moving through the different stages of testing i.e. from internal testing, through to UAT, you should suffix the application name with the appropriate stage:
Stage Testing Description Naming Convention Alpha Developer testing with project team Northwind_v2-3_alpha.exe Beta Internal “Test Please" testing with non-project working colleagues Northwind_v2-3_beta.exe Production e.g. When moving onto production, this naming convention is dropped Northwind_v2-3.exe Do you avoid using spaces in folder and file names?
It is not a good idea to have spaces in a folder or file name as they don't translate to URLs very well and can even cause technical problems.
Instead of using spaces, we recommend:
- kebab-case - using dashes between words
Other not recommended options include:
- CamelCase - using the first letter of each word in uppercase and the rest of the word in lowercase
- snake_case - using underscores between words
For further information, read Do you know how to name documents?
This rule should apply to any file or folder that is on the web. This includes Azure DevOps Team Project names and SharePoint Pages.
- extremeemailsversion1.2.doc
- Extreme Emails version 1.2.doc
❌ Figure: Bad examples - File names have spaces or dots
- extreme-emails-v1-2.doc
- Extreme-Emails-v1-2.doc
✅ Figure: Good examples - File names have dashes instead of spaces
- sharepoint.ssw.com.au/Training/UTSNET/Pages/UTS%20NET%20Short%20Course.aspx
- fileserver/Shared%20Documents/Ignite%20Brisbane%20Talk.docx
❌ Figure: Bad examples - File names have been published to the web with spaces so the URLs look ugly and are hard to read
- sharepoint.ssw.com.au/Training/UTS-NET/Pages/UTS-NET-Short-Course.aspx
- fileserver/Shared-Documents/Ignite-Brisbane-Talk.docx"
✅ Figure: Good examples - File names have no spaces so are much easier to read
Do you start versioning at 0.1 and change to 1.0 once approved by a client or tester?
Software and document version numbers should be consistent and meaningful to both the developer and the user.
Generally, version numbering should begin at 0.1. Once the project has been approved for release by the client or tester, the version number will be incremented to 1.0. The numbering after the decimal point needs to be decided on and uniform. For example, 1.1 might have many bug fixes and a minor new feature, while 1.11 might only include one minor bug fix.
Do you know how to avoid problems in if-statements?
Try to avoid problems in if-statements without curly brackets and just one statement which is written one line below the if-statement. Use just one line for such if-statements. If you want to add more statements later on and you could forget to add the curly brackets which may cause problems later on.
if (ProductName == null) ProductName = string.Empty; if (ProductVersion == null)ProductVersion = string.Empty; if (StackTrace == null) StackTrace = string.Empty;❌ Figure: Figure: Bad Example
if (ProductName == null){ProductName = string.Empty;}if (ProductVersion == null){ProductVersion = string.Empty;}if (StackTrace == null){StackTrace = string.Empty;}✅ Figure: Figure: Good Example
Do you avoid Double-Negative Conditionals in if-statements?
Try to avoid Double-Negative Conditionals in if-statements. Double negative conditionals are difficult to read because developers have to evaluate which is the positive state of two negatives. So always try to make a single positive when you write if-statement.
if (!IsValid){// handle error}else{// handle success}❌ Figure: Figure: Bad example
if (IsValid){// handle success}else{// handle error}✅ Figure: Figure: Good example
if (!IsValid){// handle error}✅ Figure: Figure: Another good example
Use pattern matching for boolean evaluations to make your code even more readable!
if (IsValid is false){// handle error}✅ Figure: Figure: Even better
C# Code - Do you use string literals?
<introEmbed body={<> Do you know String should be @-quoted instead of using escape character for "\\"? The @ symbol specifies that escape characters and line breaks should be ignored when the string is created. As per: [Strings](<https://docs.microsoft.com/en-us/previous-versions/visualstudio/visual-studio-2008/c84eby0h(v=vs.90?WT.mc_id=DT-MVP-33518)?redirectedfrom=MSDN>) </>} /> ```cs string p2 = "\\My Documents\\My Files\\"; ``` <figureEmbed figureEmbed={{ preset: "badExample", figure: 'Figure: Bad example - Using "\\"', shouldDisplay: true } } /> ```cs string p2 = @"\My Documents\My Files\"; ``` <figureEmbed figureEmbed={{ preset: "goodExample", figure: 'Figure: Good example - Using @', shouldDisplay: true } } /> ## Raw String Literals In C#11 and later, we also have the option to use raw string literals. These are great for embedding blocks of code from another language into C# (e.g. SQL, HTML, XML, etc.). They are also useful for embedding strings that contain a lot of escape characters (e.g. regular expressions). Another advantage of Raw String Literals is that the redundant whitespace is trimmed from the start and end of each line, so you can indent the string to match the surrounding code without affecting the string itself. ```cs var bad = "<html>" + "<body>" + "<p class=\"para\">Hello, World!</p>" + "</body>" + "</html>"; ``` <figureEmbed figureEmbed={{ preset: "badExample", figure: 'Figure: Bad example - Single quotes', shouldDisplay: true } } /> ```cs var good = """ <html> <body> <p class="para">Hello, World!</p> </body> </html> """; ``` <figureEmbed figureEmbed={{ preset: "goodExample", figure: 'Figure: Good example - Using raw string literals', shouldDisplay: true } } /> For more information on Raw String literals see [learn.microsoft.com/en-us/dotnet/csharp/language-reference/tokens/raw-string](https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/tokens/raw-string?WT.mc_id=DT-MVP-33518)Do you add the Application Name in the SQL Server connection string?
You should always add the application name to the connection string so that SQL Server will know which application is connecting, and which database is used by that application. This will also allow SQL Profiler to trace individual applications which helps you monitor performance or resolve conflicts.
<add key="Connection" value="Integrated Security=SSPI;Persist Security Info=False;Initial Catalog=Biotrack01;Data Source=sheep;"/>❌ Figure: Bad example - The connection string without Application Name
<add key="Connection" value="Integrated Security=SSPI;Persist SecurityInfo=False;Initial Catalog=Biotrack01;Data Source=sheep;Application Name=Biotracker"/> <!-- Good Code - Application Name is added in the connection string. -->✅ Figure: Good example - The connection string with Application Name
Do you know how to use Connection Strings?
There are 2 type of connection strings. The first contains only address type information without authorization secrets. These can use all of the simpler methods of storing configuration as none of this data is secret.
Option 1 - Using Azure Managed Identities (Recommended)
When deploying an Azure hosted application we can use Azure Managed Identities to avoid having to include a password or key inside our connection string. This means we really just need to keep the address or url to the service in our application configuration. Because our application has a Managed Identity, this can be treated in the same way as a user's Azure AD identity and specific roles can be assigned to grant the application access to required services.
This is the preferred method wherever possible, because it eliminates the need for any secrets to be stored. The other advantage is that for many services the level of access control available using Managed Identities is much more granular making it much easier to follow the Principle of Least Privilege.
Option 2 - Connection Strings with passwords or keys
If you have to use some sort of secret or key to login to the service being referenced, then some thought needs to be given to how those secrets can be secured. Take a look at Do you store your secrets securely to learn how to keep your secrets secure.
Example - Integrating Azure Key Vault into your ASP.NET Core application
In .NET 5 we can use Azure Key Vault to securely store our connection strings away from prying eyes.
Azure Key Vault is great for keeping your secrets secret because you can control access to the vault via Access Policies. The access policies allows you to add Users and Applications with customized permissions. Make sure you enable the System assigned identity for your App Service, this is required for adding it to Key Vault via Access Policies.
You can integrate Key Vault directly into your ASP.NET Core application configuration. This allows you to access Key Vault secrets via
IConfiguration.public static IHostBuilder CreateHostBuilder(string[] args) =>Host.CreateDefaultBuilder(args).ConfigureWebHostDefaults(webBuilder =>{webBuilder.UseStartup<Startup>().ConfigureAppConfiguration((context, config) =>{// To run the "Production" app locally, modify your launchSettings.json file// -> set ASPNETCORE_ENVIRONMENT value as "Production"if (context.HostingEnvironment.IsProduction()){IConfigurationRoot builtConfig = config.Build();// ATTENTION://// If running the app from your local dev machine (not in Azure AppService),// -> use the AzureCliCredential provider.// -> This means you have to log in locally via `az login` before running the app on your local machine.//// If running the app from Azure AppService// -> use the DefaultAzureCredential provider//TokenCredential cred = context.HostingEnvironment.IsAzureAppService() ?new DefaultAzureCredential(false) : new AzureCliCredential();var keyvaultUri = new Uri($"https://{builtConfig["KeyVaultName"]}.vault.azure.net/");var secretClient = new SecretClient(keyvaultUri, cred);config.AddAzureKeyVault(secretClient, new KeyVaultSecretManager());}});});✅ Figure: Good example - For a complete example, refer to this [sample application](https://github.com/william-liebenberg/keyvault-example)
Tip: You can detect if your application is running on your local machine or on an Azure AppService by looking for the
WEBSITE_SITE_NAMEenvironment variable. If null or empty, then you are NOT running on an Azure AppService.public static class IWebHostEnvironmentExtensions{public static bool IsAzureAppService(this IWebHostEnvironment env){var websiteName = Environment.GetEnvironmentVariable("WEBSITE_SITE_NAME");return string.IsNullOrEmpty(websiteName) is not true;}}Setting up your Key Vault correctly
In order to access the secrets in Key Vault, you (as User) or an Application must have been granted permission via a Key Vault Access Policy.
Applications require at least the LIST and GET permissions, otherwise the Key Vault integration will fail to retrieve secrets.
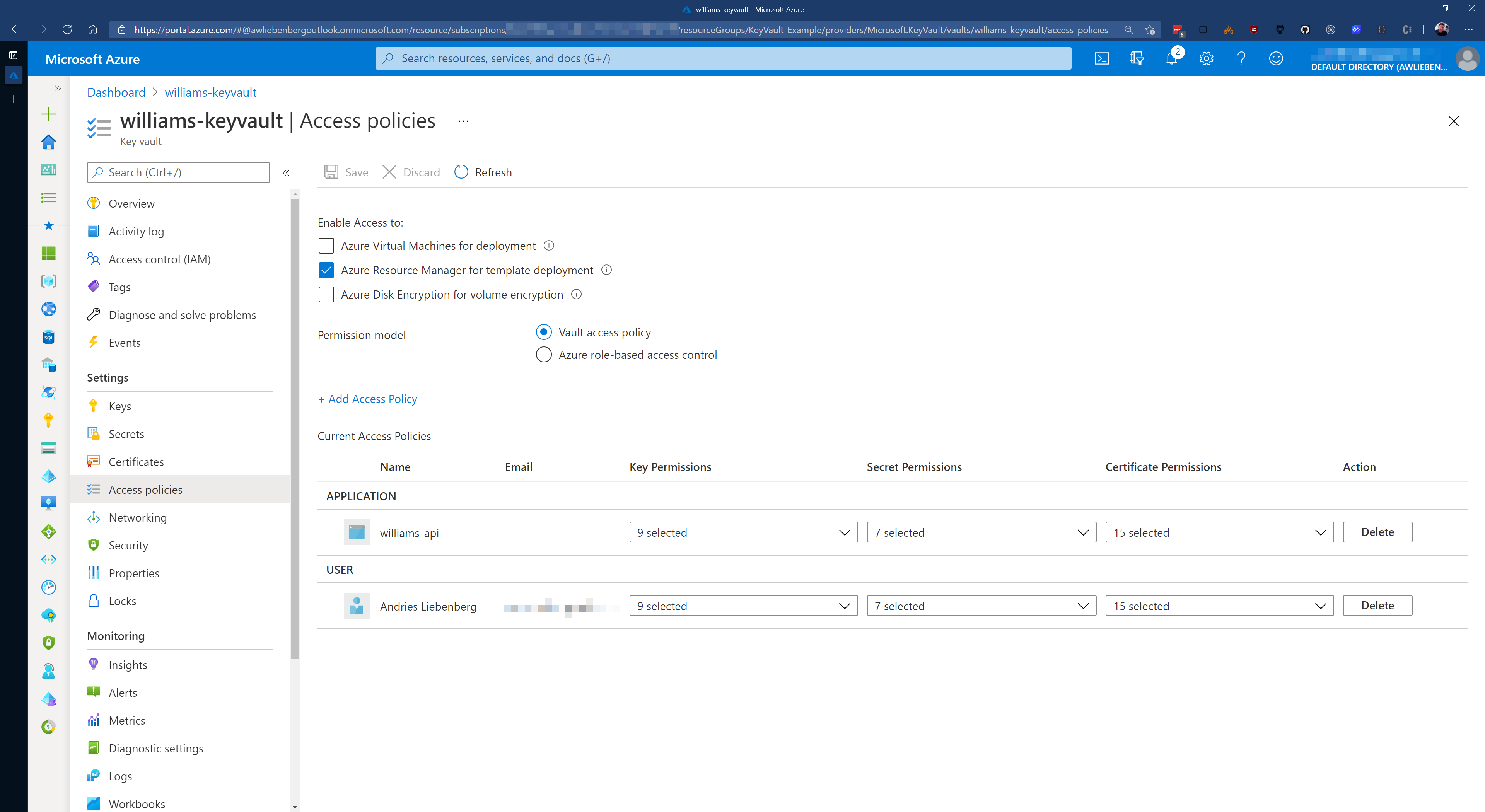
Figure: Key Vault Access Policies - Setting permissions for Applications and/or Users
Azure Key Vault and App Services can easily trust each other by making use of System assigned Managed Identities. Azure takes care of all the complicated logic behind the scenes for these two services to communicate with each other - reducing the complexity for application developers.
So, make sure that your Azure App Service has the System assigned identity enabled.
Once enabled, you can create a Key Vault Access policy to give your App Service permission to retrieve secrets from the Key Vault.
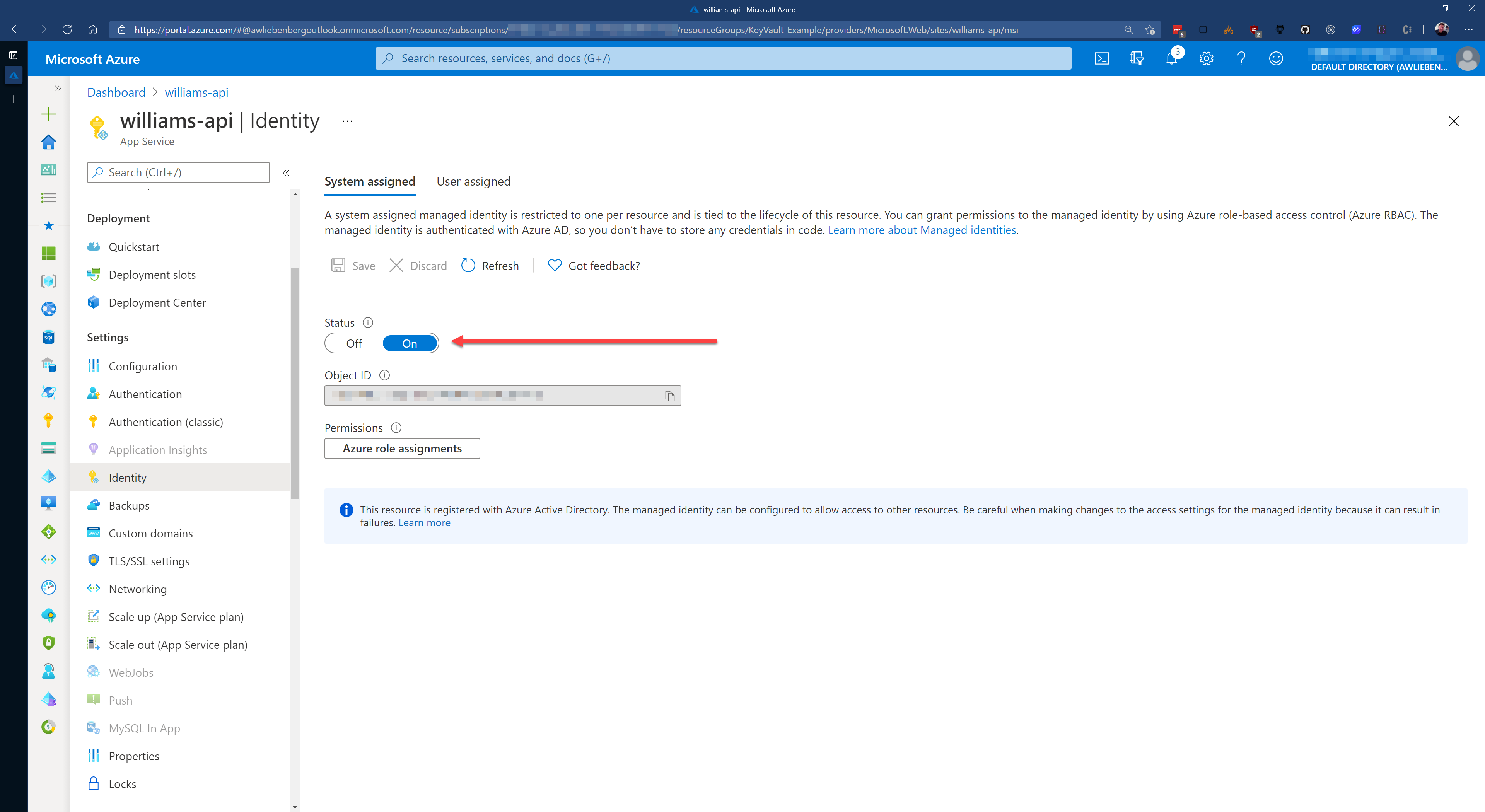
Figure: Enabling the System assigned identity for your App Service - this is required for adding it to Key Vault via Access Policies
Adding secrets into Key Vault is easy.
- Create a new secret by clicking on the Generate/Import button
- Provide the name
- Provide the secret value
- Click Create
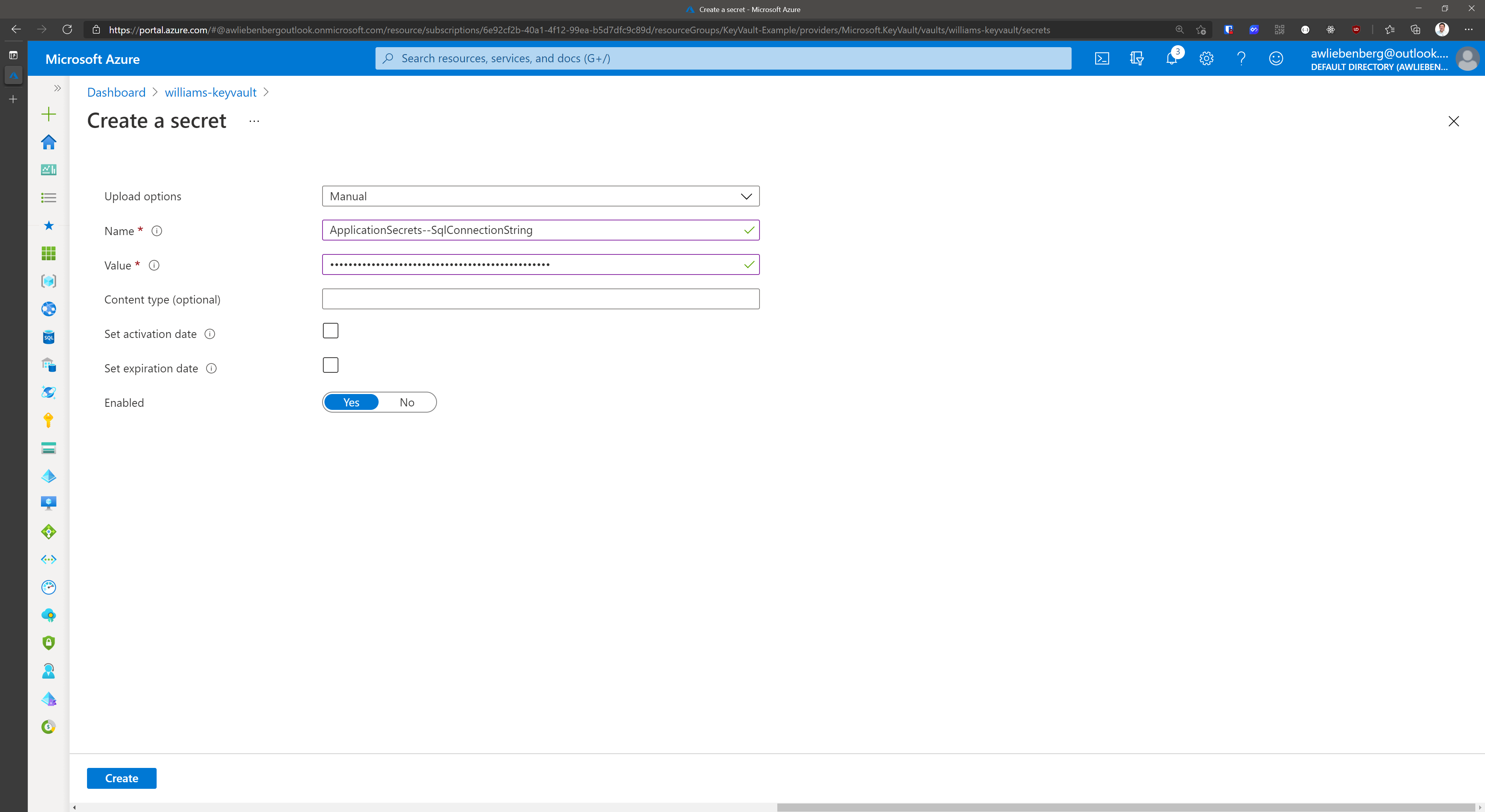
Figure: Creating the SqlConnectionString secret in Key Vault.
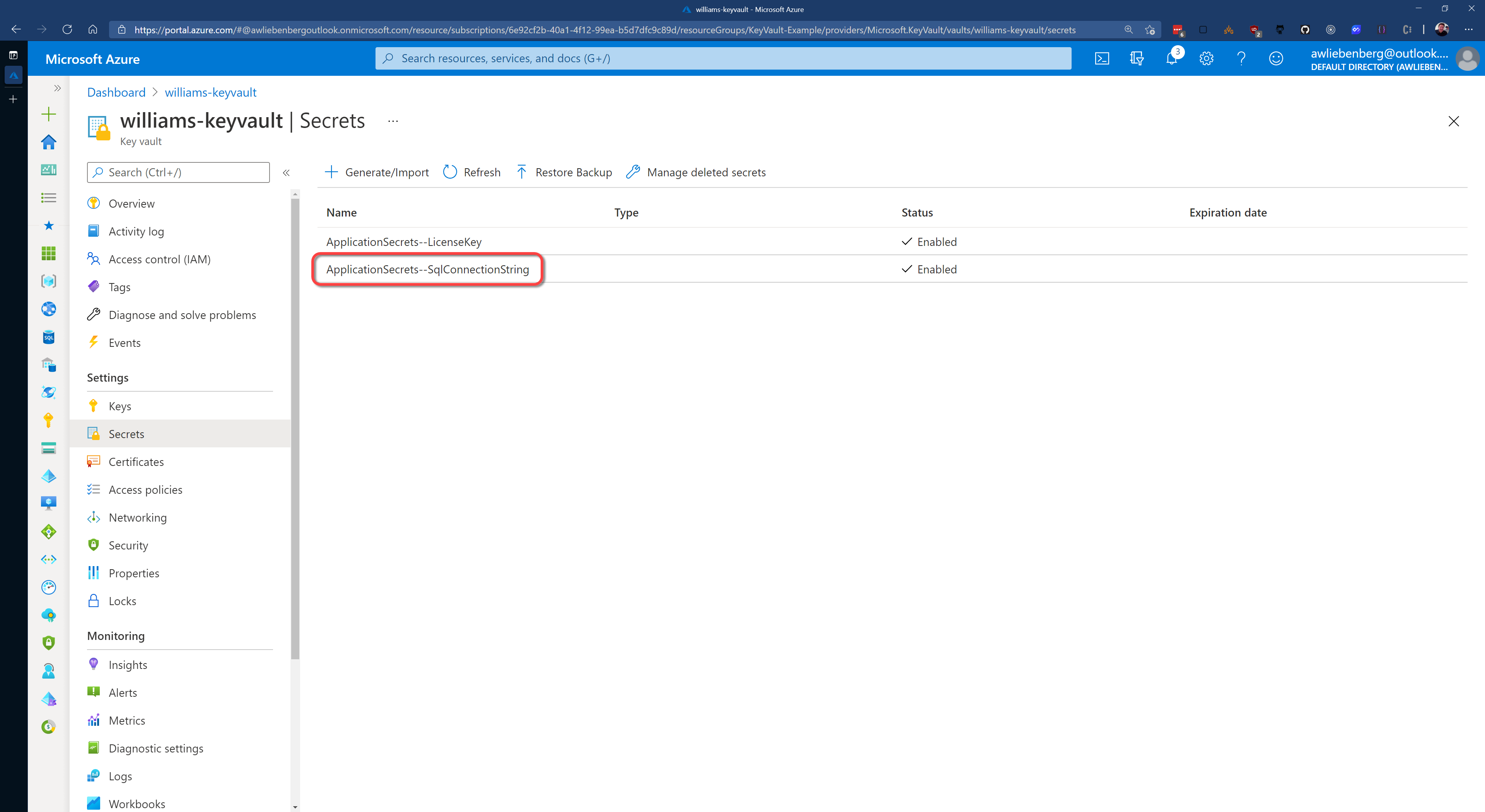
Figure: SqlConnectionString stored in Key Vault
Note: The ApplicationSecrets section is indicated by "ApplicationSecrets--" instead of "ApplicationSecrets:".
As a result of storing secrets in Key Vault, your Azure App Service configuration (app settings) will be nice and clean. You should not see any fields that contain passwords or keys. Only basic configuration values.
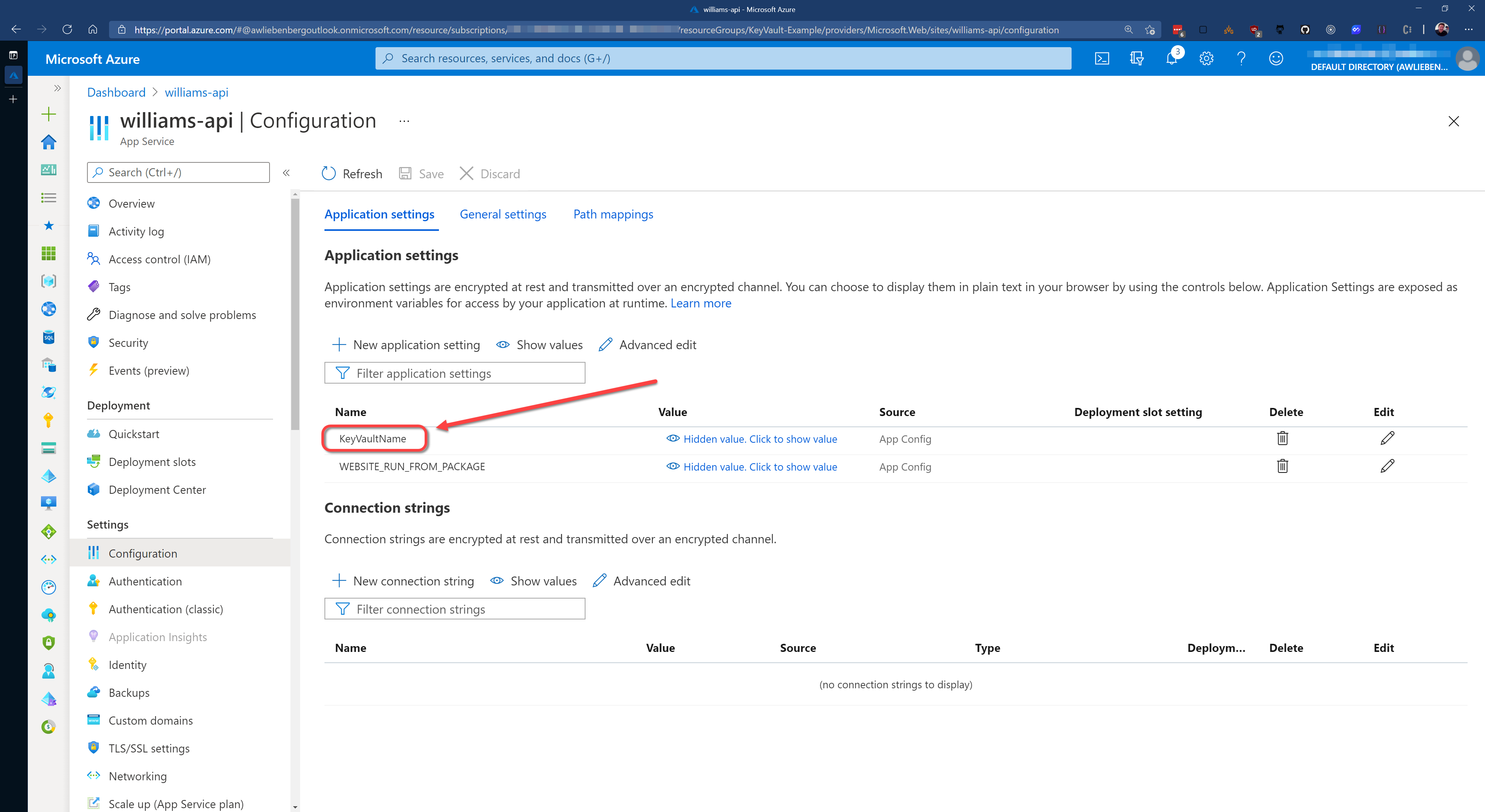
Figure: Your WebApp Configuration - No passwords or secrets, just a name of the Key vault that it needs to access
Video: Watch SSW's William Liebenberg explain Connection Strings and Key Vault in more detail (8 min)History of Connection Strings
In .NET 1.1 we used to store our connection string in a configuration file like this:
<configuration><appSettings><add key="ConnectionString" value ="integrated security=true;data source=(local);initial catalog=Northwind"/></appSettings></configuration>...and access this connection string in code like this:
SqlConnection sqlConn =new SqlConnection(System.Configuration.ConfigurationSettings.AppSettings["ConnectionString"]);❌ Figure: Historical example - Old ASP.NET 1.1 way, untyped and prone to error
In .NET 2.0 we used strongly typed settings classes:
Step 1: Setup your settings in your common project. E.g. Northwind.Common

Figure: Settings in Project Properties
Step 2: Open up the generated App.config under your common project. E.g. Northwind.Common/App.config
Step 3:
Copy the content into your entry applications app.config. E.g. Northwind.WindowsUI/App.configThe new setting has been updated to app.config automatically in .NET 2.0<configuration><connectionStrings><add name="Common.Properties.Settings.NorthwindConnectionString"connectionString="Data Source=(local);Initial Catalog=Northwind;Integrated Security=True"providerName="System.Data.SqlClient" /></connectionStrings></configuration>...then you can access the connection string like this in C#:
SqlConnection sqlConn =new SqlConnection(Common.Properties.Settings.Default.NorthwindConnectionString);❌ Figure: Historical example - Access our connection string by strongly typed generated settings class...this is no longer the best way to do it
Do you store your secrets securely?
<introEmbed body={<> Most systems will have variables that need to be stored securely; OpenId shared secret keys, connection strings, and API tokens to name a few. These secrets **must not** be stored in source control. It is insecure and means they are sitting out in the open, wherever code has been downloaded, for anyone to see. </>} /> There are many options for managing secrets in a secure way: ### Bad Practices <asideEmbed variant="greybox" body={<> #### Store production passwords in source control Pros: * Minimal change to existing process * Simple and easy to understand Cons: * Passwords are readable by anyone who has either source code or access to source control * Difficult to manage production and non-production config settings * Developers can read and access the production password  </>} figureEmbed={{ preset: "badExample", figure: 'Bad practice - Overall rating: 1/10', shouldDisplay: true }} /> <asideEmbed variant="greybox" body={<> #### Store production passwords in source control protected with the [ASP.NET IIS Registration Tool](https://docs.microsoft.com/en-us/previous-versions/zhhddkxy(v=vs.140?WT.mc_id=DT-MVP-33518)?redirectedfrom=MSDN) Pros: * Minimal change to existing process – no need for [DPAPI](https://docs.microsoft.com/en-us/aspnet/core/security/data-protection/introduction?view=aspnetcore-5.0&WT.mc_id=ES-MVP-33518) or a dedicated Release Management (RM) tool * Simple and easy to understand Cons: * Need to manually give the app pool identity ability to read the default RSA key container * Difficult to manage production and non-production config settings * Developers can easily decrypt and access the production password * Manual transmission of the password from the key store to the encrypted config file </>} figureEmbed={{ preset: "badExample", figure: 'Bad practice - Overall rating: 2/10', shouldDisplay: true }} /> <asideEmbed variant="greybox" body={<> #### Use Windows Identity instead of username / password Pros: * Minimal change to existing process – no need for DPAPI or a dedicated RM tool * Simple and easy to understand Cons: * Difficult to manage production and non-production config settings * Not generally applicable to all secured resources * Can hit firewall snags with Kerberos and AD ports * Vulnerable to DOS attacks related to password lockout policies * Has key-person reliance on network admin </>} figureEmbed={{ preset: "badExample", figure: 'Bad practice - Overall rating: 4/10', shouldDisplay: true }} /> <asideEmbed variant="greybox" body={<> #### [Use External Configuration Files](https://docs.microsoft.com/en-us/aspnet/identity/overview/features-api/best-practices-for-deploying-passwords-and-other-sensitive-data-to-aspnet-and-azure?WT.mc_id=DT-MVP-33518) Pros: * Simple to understand and implement Cons: * Makes setting up projects the first time very hard * Easy to accidentally check the external config file into source control * Still need DPAPI to protect the external config file * No clear way to manage the DevOps process for external config files </>} figureEmbed={{ preset: "default", figure: 'XXX', shouldDisplay: false }} /> <figureEmbed figureEmbed={{ preset: "badExample", figure: 'Figure: Bad practice - Overall rating: 1/10', shouldDisplay: true } } /> ### Good Practices <asideEmbed variant="greybox" body={<> #### Use Octopus/ VSTS RM secret management, with passwords sourced from KeePass Pros: * Scalable and secure * General industry best practice - great for organizations of most sizes below large corporate Cons: * Password reset process is still manual * DPAPI still needed </>} figureEmbed={{ preset: "goodExample", figure: 'Good practice - Overall rating: 8/10', shouldDisplay: true }} /> <asideEmbed variant="greybox" body={<> #### Use Enterprise Secret Management Tool – Keeper, 1Password, LastPass, Hashicorp Vault, etc Pros: * Enterprise grade – supports cryptographically strong passwords, auditing of secret access and dynamic secrets * Supports hierarchy of secrets * API interface for interfacing with other tools * Password transmission can be done without a human in the chain Cons: * More complex to install and administer * DPAPI still needed for config files at rest </>} figureEmbed={{ preset: "goodExample", figure: 'Good practice - Overall rating: 8/10', shouldDisplay: true }} /> <asideEmbed variant="greybox" body={<> #### Use .NET User Secrets Pros: * Simple secret management for development environments * Keeps secrets out of version control Cons: * Not suitable for production environments </>} figureEmbed={{ preset: "goodExample", figure: 'Good practice - Overall rating 8/10', shouldDisplay: true }} /> <asideEmbed variant="greybox" body={<> #### Use Azure Key Vault See the [SSW Rewards](https://www.ssw.com.au/ssw/Rewards/) mobile app repository for how SSW is using this in a production application: <https://github.com/SSWConsulting/SSW.Rewards> Pros: * Enterprise grade * Uses industry standard best encryption * Dynamically cycles secrets * Access granted based on Azure AD permissions - no need to 'securely' share passwords with colleagues * Can be used to inject secrets in your CI/CD pipelines for non-cloud solutions * Can be used by on-premise applications (more configuration - see [Use Application ID and X.509 certificate for non-Azure-hosted apps](https://learn.microsoft.com/en-us/aspnet/core/security/key-vault-configuration?view=aspnetcore-7.0#use-application-id-and-x509-certificate-for-non-azure-hosted-apps&WT.mc_id=ES-MVP-33518)) Cons: * Tightly integrated into Azure so if you are running on another provider or on premises, this may be a concern. Authentication into Key Vault now needs to be secured. </>} figureEmbed={{ preset: "goodExample", figure: 'Good practice - Overall rating 9/10', shouldDisplay: true }} /> <asideEmbed variant="greybox" body={<> #### Avoid using secrets with Azure Managed Identities The easiest way to manage secrets is not to have them in the first place. Azure Managed Identities allows you to assign an Azure AD identity to your application and then allow it to use its identity to log in to other services. This avoids the need for any secrets to be stored. Pros: * Best solution for cloud (Azure) solutions * Enterprise grade * Access granted based on Azure AD permissions - no need to 'securely' share passwords with colleagues * Roles can be granted to your application your CI/CD pipelines at the time your services are deployed Cons: * Only works where Azure AD RBAC is available. NB. There are still some Azure services that don't yet support this. Most do though.  </>} figureEmbed={{ preset: "goodExample", figure: 'Good practice - Overall rating 10/10', shouldDisplay: true }} /> ### Resources The following resources show some concrete examples on how to apply the principles described: * [github.com/brydeno/bicepsofsteel](https://github.com/brydeno/bicepsofsteel) * [Microsoft Learn | Best practices for using Azure Key Vault](https://learn.microsoft.com/en-us/azure/key-vault/general/best-practices?WT.mc_id=DT-MVP-33518) * [Microsoft Learn | Azure Key Vault security](https://learn.microsoft.com/en-us/azure/key-vault/general/security-features?WT.mc_id=DT-MVP-33518) * [Microsoft Learn | Safe storage of app secrets in development in ASP.NET Core](https://learn.microsoft.com/en-us/aspnet/core/security/app-secrets?view=aspnetcore-5.0&tabs=windows&WT.mc_id=ES-MVP-33518) * [Microsoft Learn | Connection strings and configuration files](https://learn.microsoft.com/en-us/sql/connect/ado-net/connection-strings-and-configuration-files?view=sql-server-ver15&WT.mc_id=DT-MVP-33518) * [Microsoft Learn | Use managed identities to access App Configuration](https://learn.microsoft.com/en-us/azure/azure-app-configuration/howto-integrate-azure-managed-service-identity?tabs=core5x&pivots=framework-dotnet&WT.mc_id=AZ-MVP-33518) * [Stop storing your secrets with Azure Managed Identities | Bryden Oliver](https://www.youtube.com/watch?v=F9H0txgz0ns)Do you share your developer secrets securely?
You may be asking what's a secret for a development environment? A developer secret is any value that would be considered sensitive.
Most systems will have variables that need to be stored securely; OpenId shared secret keys, connection strings, and API tokens to name a few. These secrets must not be stored in source control. It's not secure and means they are sitting out in the open, wherever code has been downloaded, for anyone to see.
There are different ways to store your secrets securely. When you use .NET User Secrets, you can store your secrets in a JSON file on your local machine. This is great for development, but how do you share those secrets securely with other developers in your organization?
Video: Do you share secrets securely | Jeoffrey Fischer (7min)An encryption key or SQL connection string to a developer's local machine/container is a good example of something that will not always be sensitive for in a development environment, whereas a GitHub PAT token or Azure Storage SAS token would be considered sensitive as it allows access to company-owned resources outside of the local development machine.
❌ Bad practices
❌ Do not store secrets in appsettings.Development.json
The
appsettings.Development.jsonfile is meant for storing development settings. It is not meant for storing secrets. This is a bad practice because it means that the secrets are stored in source control, which is not secure.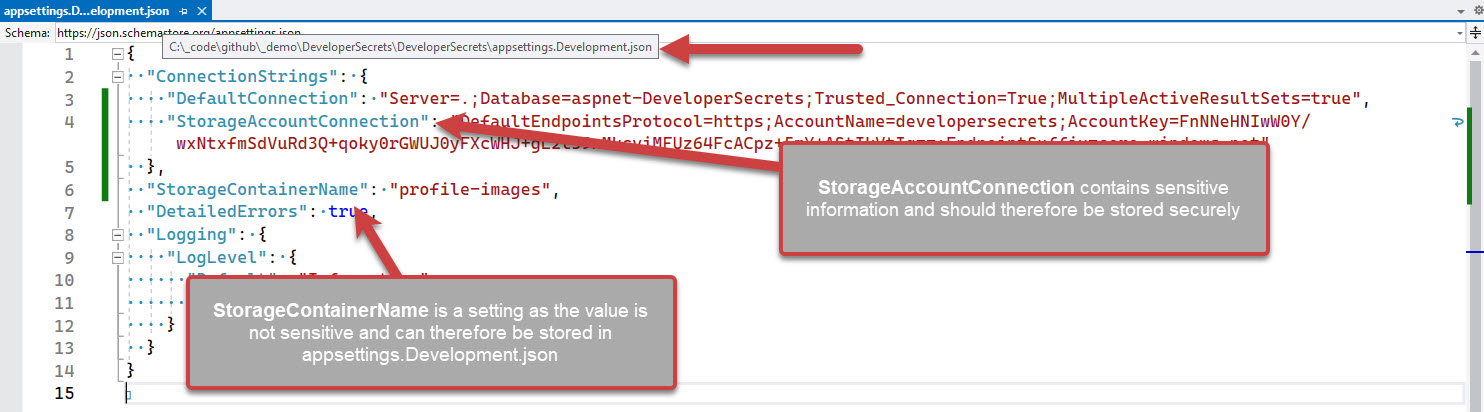
❌ Figure: Bad practice - Overall rating: 1/10
❌ Do not share secrets via email/Microsoft Teams
Sending secrets over Microsoft Teams is a terrible idea, the messages can land up in logs, but they are also stored in the chat history. Developers can delete the messages once copied out, although this extra admin adds friction to the process and is often forgotten.
Note: Sending the secrets in email, is less secure and adds even more admin for trying to remove some of the trace of the secret and is probably the least secure way of transferring secrets.
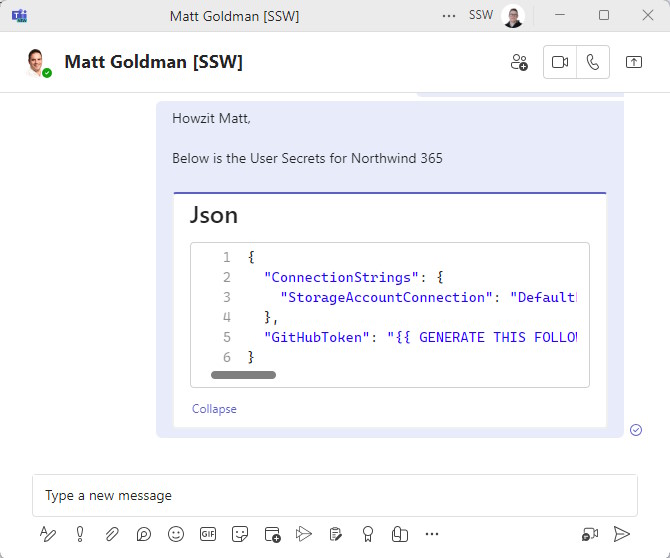
❌ Figure: Bad practice - Overall rating: 3/10
✅ Good practices
✅ Remind developers where the secrets are for a project
For development purposes once you are using .NET User Secrets you will still need to share them with other developers on the project.
<imageEmbed alt="Image" size="large" showBorder={false} figureEmbed={{ preset: "default", figure: 'User Secrets are stored outside the development folder', shouldDisplay: true }} src="/uploads/rules/share-your-developer-secrets-securely/user-secrets.jpg" />As a way of giving a heads up to other developers on the project, you can add a step in your
_docs\Instructions-Compile.mdfile (see rule on making awesome documentation) to inform developers to get a copy of the user secrets. You can also add a placeholder to theappsettings.Development.jsonfile to remind developers to add the secrets.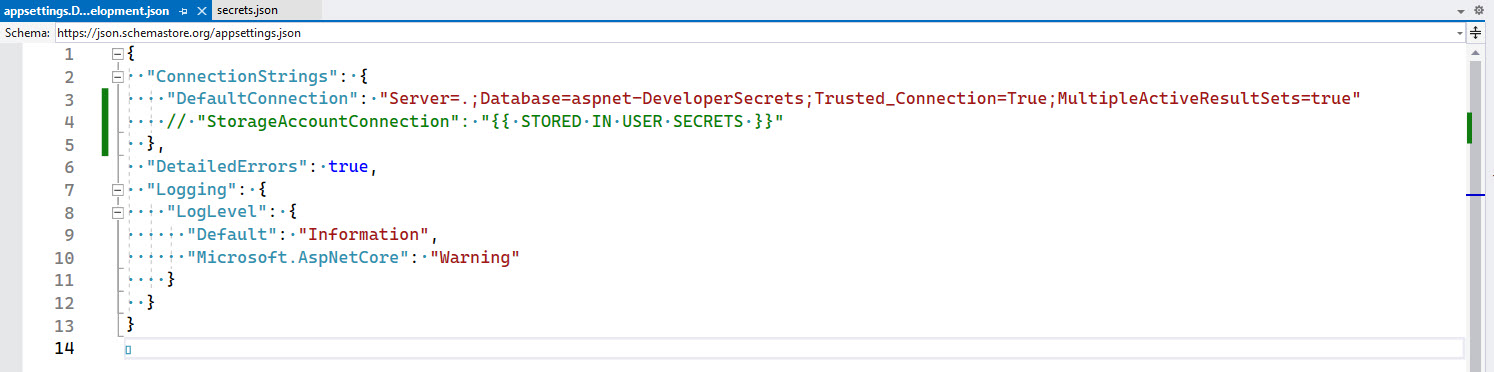
✅ Figure: Good practice - Remind developers where the secrets are for this project
✅ Use 1ty.me to share secrets securely
Using a site like 1ty.me allows you to share secrets securely with other developers on the project.
Pros:
- Simple to share secrets
- Free
Cons:
- Requires a developer to have a copy of the
secrets.jsonfile already - Developers need to remember to add placeholders for developer specific secrets before sharing
- Access Control - Although the link is single use, there's no absolute guarantee that the person opening the link is authorized to do so
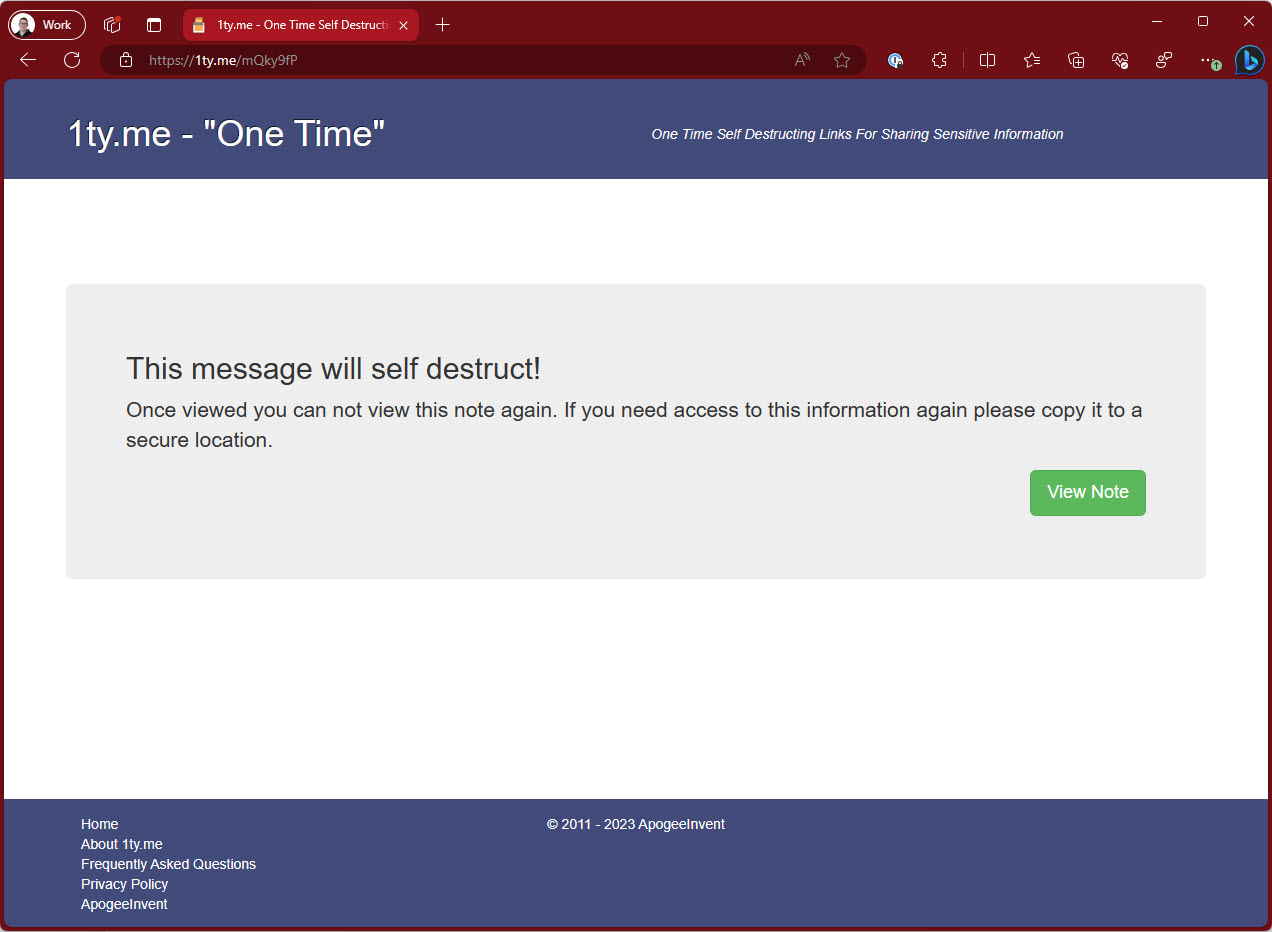
✅ Figure: Good practice - Overall rating 8/10
✅ Use Azure Key Vault
Azure Key Vault is a great way to store secrets securely. It is great for production environments, although for development purposes it means you would have to be online at all times.
Pros:
- Enterprise grade
- Uses industry standard best encryption
- Dynamically cycles secrets
- Access Control - Access granted based on Azure AD permissions - no need to 'securely' share passwords with colleagues
Cons:
- Not able to configure developer specific secrets
- No offline access
- Tightly integrated into Azure so if you are running on another provider or on premises, this may be a concern
- Authentication into Key Vault requires Azure service authentication, which isn't supported in every IDE
✅ Figure: Good practice - Overall rating 8/10
✅ (Recommended) Use Enterprise Secret Management Tool – Keeper, 1Password, LastPass, Hashicorp Vault, etc
Enterprise Secret Management tools have are great for storing secrets for various systems across the whole organization. This includes developer secrets
Pros:
- Developers don't need to call other developers to get secrets
- Placeholders can be placed in the stored secrets
- Access Control - Only developers who are authorized to access the secrets can do so
Cons:
- More complex to install and administer
- Paid Service
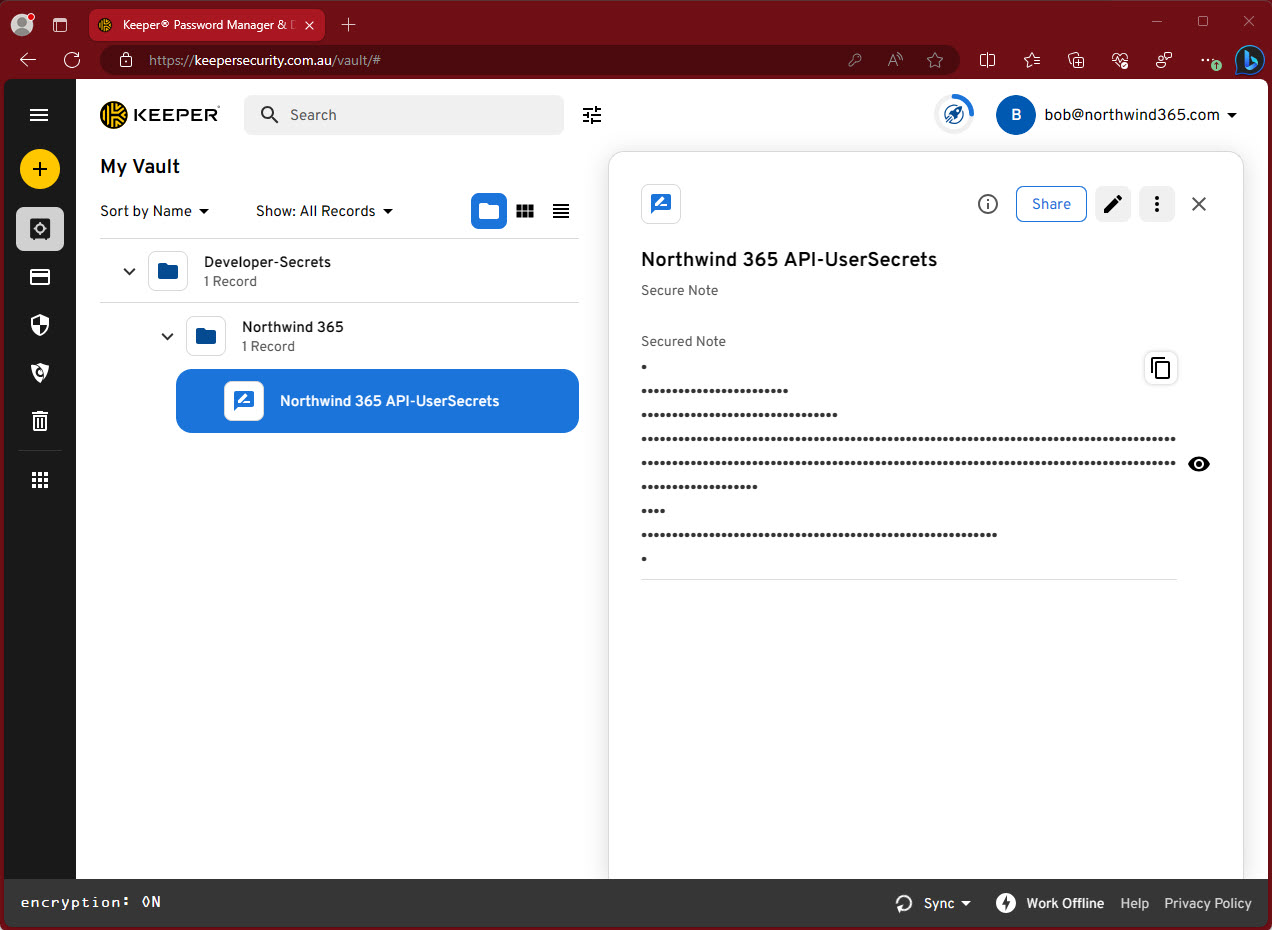
✅ Figure: Good practice - Overall rating 10/10
Tip: You can store the full
secrets.jsonfile contents in the enterprise secrets management tool.Most enterprise secrets management tool have the ability to retrieve the secrets via an API, with this you could also store the
UserSecretIdin a field and create a script that updates the secrets easily into the correctsecrets.jsonfile on your development machine.Do you avoid clear text email addresses in web pages?
Clear text email addresses in web pages are very dangerous because it gives spam sender a chance to pick up your email address, which produces a lot of spam/traffic to your mail server, this will cost you money and time to fix.
Never put clear text email addresses on web pages.
<!--SSW Code Auditor - Ignore next line(HTML)--><a href="mailto:test@ssw.com.au">Contact Us</a>❌ Figure: Bad - Using a plain email address that it will be crawled and made use of easily
<a href="javascript:sendEmail('74657374407373772e636f6d2e6175')" onmouseover="javascript:displayStatus('74657374407373772e636f6d2e6175');return true;" onmouseout="javascript:clearStatus(); return true;">Contact Us</a>✅ Figure: Good - Using an encoded email address
Tip: If you use Wordpress, use the Email Encoder Bundle plugin to help you encode email addresses easily.
We have a program called SSW CodeAuditor to check for this rule.
Do you always create suggestions when something is hard to do?
One of our goals is to make the job of the developer as easy as possible. If you have to write a lot of code for something that you think you should not have to do, you should make a suggestion and add it to the relevant page.
If you have to add a suggestion, make sure that you put the link to that suggestion into the comments of your code.
/// <summary>/// base class for command implementations/// This is a work around as standard MVVM commands/// are not provided by default./// </summary>public class Command : ICommand{// code}❌ Figure: Figure: Bad example - The link to the suggestion should be in the comments
/// <summary>/// base class for command implementations/// This is a work around as standard MVVM commands/// are not provided by default./// </summary>////// <remarks>/// Issue Logged here: https://github.com/SSWConsulting/SSW.Rules/issues/3///</remarks>public class Command : ICommand{// code}✅ Figure: Figure: Good example - When you link to a suggestion everyone can find it and vote it up
Do you avoid casts and use the "as operator" instead?
Use casts only if: a. You know 100% that you get that type back b. You want to perform a user-defined conversion
private void AMControlMouseLeftButtonUp(object sender, MouseButtonEventArgs e){var auc = (AMUserControl)sender;var aucSessionId = auc.myUserControl.Tag;// snip snip snip}❌ Figure: Bad example
private void AMControlMouseLeftButtonUp(object sender, MouseButtonEventArgs e){var auc = sender as AMUserControl;if (auc != null){var aucSessionId = auc.myUserControl.Tag;// snip snip snip}}✅ Figure: Good example
More info here: http://blog.gfader.com/2010/08/avoid-type-casts-use-operator-and-check.html
Do you avoid Empty code blocks?
Empty Visual C# .NET methods consume program resources unnecessarily. Put a comment in code block if its stub for future application. Don’t add empty C# methods to your code. If you are adding one as a placeholder for future development, add a comment with a TODO.
Also, to avoid unnecessary resource consumption, you should keep the entire method commented until it has been implemented.
If the class implements an inherited interface method, ensure the method throws NotImplementedException.
public class Example{public double salary(){}}❌ Figure: Figure: Bad Example - Method is empty
public class Sample{public double salary(){return 2500.00;}}✅ Figure: Figure: Good Example - Method implements some code
public interface IDemo{void DoSomethingUseful();void SomethingThatCanBeIgnored();}public class Demo : IDemo{public void DoSomethingUseful(){// no audit issuesConsole.WriteLine("Useful");}// audit issuespublic void SomethingThatCanBeIgnored(){}}❌ Figure: Figure: Bad Example - No Comment within empty code block
public interface IDemo{void DoSomethingUseful();void SomethingThatCanBeIgnored();}public class Demo : IDemo{public void DoSomethingUseful(){// no audit issuesConsole.WriteLine("Useful");}// No audit issuespublic void SomethingThatCanBeIgnored(){// stub for IDemo interface}}✅ Figure: Figure: Good Example - Added comment within Empty Code block method of interface class
Do you avoid logic errors by using Else If?
We see a lot of programmers doing this, they have two conditions - true and false - and they do not consider other possibilities - e.g. an empty string. Take a look at this example. We have an If statement that checks what backend database is being used.
In the example the only expected values are "Development" and "Production".
void Load(string environment){if (environment == "Development"){// set Dev environment variables}else{// set Production environment variables}}❌ Figure: Figure: Bad example with If statement
Consider later that extra environments may be added: e.g. "Staging"
By using the above code, the wrong code will run because the above code assumes two possible situations. To avoid this problem, change the code to be defensive .g. Use an Else If statement (like below).
Now the code will throw an exception if an unexpected value is provided.
void Load(string environment){if (environment == "Development"){// set Dev environment variables}else if (environment == "Production"){// set Production environment variables}else{throw new InvalidArgumentException(environment);}}✅ Figure: Figure: Good example with If statement
Do you avoid putting business logic into the presentation layer?
Be sure you are aware of what is business logic and what isn't. Typically, looping code will be placed in the business layer. This ensures that no redundant code is written and other projects can reference this logic as well.
private void btnOK_Click(object sender, EventArgs e){rtbParaText.Clear();var query =from p in dc.GetTable()select p.ParaID;foreach (var result in query){var query2 =from t in dc.GetTable()where t.ParaID == resultselect t.ParaText;rtbParaText.AppendText(query2.First() + "\r\n");}}❌ Figure: Bad Example: A UI method mixed with business logics
private void btnOK_Click(object sender, EventArgs e){string paraText = Business.GetParaText();rtbParaText.Clear();rtbParaText.Add(paraText);}✅ Figure: Good Example : Putting business logics into the business project, just call the relevant method when needed
Do you avoid "UI" in event names?
No "UI" in event names, the event raiser should be unaware of the UI in MVVM and user controls The handler of the event should then do something on the UI.
private void RaiseUIUpdateBidButtonsRed() {if (UIUpdateBidButtonsRed != null) {UIUpdateBidButtonsRed();}}❌ Figure: Bad example: Avoid "UI" in event names, an event is UI un-aware
private void RaiseSelectedLotUpdated() {if (SelectedLotUpdated != null) {SelectedLotUpdated();}}✅ Figure: Good example: When receiving an update on the currently selected item, change the UI correspondingly (or even better: use MVVM and data binding)
Do you know when to use switch statement instead of if-else?
The .NET framework and the C# language provide two methods for conditional handling where multiple distinct values can be selected from. The
switchstatement is less flexible than theif-else-iftree but is generally considered to be more efficient.The .NET compiler generates a jump list for switch blocks, resulting in far better performance than if/else for evaluating conditions. The performance gains are negligible when the number of conditions is trivial (i.e. fewer than 5), so if the code is clearer and more maintainable using if/else blocks, then you can use your discretion. But be prepared to refactor to a switch block if the number of conditions exceeds 5.
int DepartmentId = GetDepartmentId()if(DepartmentId == 1){// do something}else if(DepartmentId == 2){// do something #2}else if(DepartmentId == 3){// do something #3}else if(DepartmentId == 4){// do something #4}else if(DepartmentId == 5){// do something #5}else{// do something #6}❌ Figure: Figure: Bad example of coding practice
int DepartmentId = GetDepartmentId()switch(DepartmentId){case 1:// do somethingbreak;case 2:// do something # 2break;case 3:// do something # 3break;case 4:// do something # 4break;case 5:// do something # 5break;case 6:// do something # 6break;default://Do something herebreak;}✅ Figure: Figure: Good example of coding practice which will result better performance
In situation where your inputs have a very skewed distribution,
if-else-ifcould outperformswitchstatement by offering a fast path. Ordering yourifstatement with the most frequent condition first will give priority to tests upfront, whereasswitchstatement will test all cases with equal priority.Do you avoid validating XML documents unnecessarily?
Validating an XML document against a schema is expensive, and should not be done where it is not absolutely necessary. Combined with weight the XML document object, validation can cause a significant performance hit:
- Read with XmlValidatingReader: 172203 nodes - 812 ms
- Read with XmlTextReader: 172203 nodes - 320 ms
- Parse using XmlDocument no validation - length 1619608 - 1052 ms
- Parse using XmlDocument with XmlValidatingReader: length 1619608 - 1862 ms
You can disable validation when using the XmlDocument object by passing an XmlTextReader instead of the XmlValidatingTextReader:
XmlDocument report = new XmlDocument();XmlTextReader tr = new XmlTextReader(Configuration.LastReportPath);report.Load(tr);To perform validation:
XmlDocument report = new XmlDocument();XmlTextReader tr = new XmlTextReader(Configuration.LastReportPath);XmlValidatingReader reader = new XmlValidatingReader(tr);report.Load(reader);The XSD should be distributed in the same directory as the XML file and a relative path should be used:
<Report> <Report xmlns="LinkAuditorReport.xsd">... </Report>Do you change the connection timeout to 5 seconds?
By default, the connection timeout is 15 seconds. When it comes to testing if a connection is valid or not, 15 seconds is a long time for the user to wait. You should change the connection timeout inside your connection strings to 5 seconds.
"Integrated Security=SSPI;Initial Catalog=SallyKnoxMedical;Data Source=TUNA"❌ Figure: Figure: Bad Connection String
"Integrated Security=SSPI;Initial Catalog=SallyKnoxMedical;Data Source=TUNA;Connect Timeout=5"✅ Figure: Figure: Good Connection String with a 5-second connection timeout
Do you declare member accessibility for all classes?
Not explicitly specifying the access type for members of a structure or class can be misleading for other developers. The default member accessibility level for classes and structs in Visual C# .NET is always private. In Visual Basic .NET, the default for classes is private, but for structs is public.
Match MatchExpression(string input, string pattern)❌ Figure: Figure: Bad - Method without member accessibility declared
private Match MatchExpression(string input, string pattern)✅ Figure: Figure: Good - Method with member accessibility declared

Figure: Compiler warning given for not explicitly defining member access level
We have a program called SSW Code Auditor to check for this rule.
Do you do your validation with Return?
The return statement can be very useful when used for validation filtering.
Instead of a deep nested If, use Return to provide a short execution path for conditions which are invalid.
private void AssignRightToLeft(){// Validate Rightif (paraRight.SelectedIndex >= 0){// Validate Leftif (paraLeft.SelectedIndex >= 0){string paraId = paraRight.SelectedValue.ToString();Paragraph para = new Paragraph();para.MoveRight(paraId);RefreshData();}}}❌ Figure: Figure: Bad example - Using nested if for validation
private void AssignRightToLeft(){// Validate Rightif (paraRight.SelectedIndex < 0){return;}// Validate Leftif (paraLeft.SelectedIndex < 0){return;}string paraId = paraRight.SelectedValue.ToString();Paragraph para = new Paragraph();para.MoveRight(paraId);RefreshData();}✅ Figure: Figure: Good example - Using Return to exit early if invalid
Do you expose events as events?
You should expose events as events.
public Action< connectioninformation > ConnectionProblem;❌ Figure: Bad code
public event Action< connectioninformation > ConnectionProblem;✅ Figure: Good code
Do you follow the boy scout rule?
This rule is inspired by a piece from Robert C. Martin (Uncle Bob) where he identifies an age old boys scouts rule could be used by software developers to constantly improve a codebase.
Uncle Bob proposed the original rule...
Always leave the campground cleaner than you found it.
...be changed to
Always leave the code you've worked on cleaner than you found it.
The reasoning being that no matter how good of a software developer we are, over time, smells creep into code. Be it from tight deadlines, old code that has been changed or appended to in insolation 100's of times over years or just or just newer & better ways of doing things become available.
So each time you touch some code, leave it just a little cleaner than the way you found it.
Here are some simple examples of how you can leave your
campsitecode cleaner:- Remove a compiler warning
- Remove unused code
- Improve variable/method naming to make it clearer
- DRY out some code
- Restructure a code block to make it more readable
- Add a test for a missing use case
Do you follow naming conventions for your Boolean Property?
Boolean Properties must be prefixed by a verb. Verbs like "Supports", "Allow", "Accept", "Use" should be valid. Also properties like "Visible", "Available" should be accepted (maybe not). See how to name Boolean columns in SQL databases.
public bool Enable { get; set; }public bool Invoice { get; set; }❌ Figure: Bad example - Not using naming convention for Boolean Property
public bool Enabled { get; set; }public bool IsInvoiceSent { get; set; }✅ Figure: Good example - Using naming convention for Boolean Property
Naming Boolean state Variables in Frontend code
When it comes to state management in frameworks like Angular or React, a similar principle applies, but with a focus on the continuity of the action.
For instance, if you are tracking a process or a loading state, the variable should reflect the ongoing nature of these actions. Instead of "isLoaded" or "isProcessed," which suggest a completed state, use names like "isLoading" or "isProcessing."
These names start as false, change to true while the process is ongoing, and revert to false once completed.
const [isLoading, setIsLoading] = useState(false); // Initial state: not loadingNote: When an operation begins, isLoading is set to true, indicating the process is active. Upon completion, it's set back to false.
This naming convention avoids confusion, such as a variable named isLoaded that would be true before the completion of a process and then false, which is counterintuitive and misleading.
We have a program called SSW CodeAuditor to check for this rule.
Do you format "Environment.NewLine" at the end of a line?
<introEmbed body={<> You should format "Environment.NewLine" at the end of a line. </>} /> ```csharp string message = "The database is not valid." + Environment.NewLine + "Do you want to upgrade it? "; ``` <figureEmbed figureEmbed={{ preset: "badExample", figure: 'Bad example - "Environment.NewLine" isn\'t at the end of the line', shouldDisplay: true } } /> ```csharp string message = "The database is not valid." + Environment.NewLine; message += "Do you want to upgrade it? "; ``` <figureEmbed figureEmbed={{ preset: "goodExample", figure: 'Good example - "Environment.NewLine" is at the end of the line', shouldDisplay: true } } /> ```csharp return string.Join(Environment.NewLine, paragraphs); ``` <figureEmbed figureEmbed={{ preset: "goodExample", figure: 'Good example - "Environment.NewLine" is an exception for String.Join\', shouldDisplay: true } } />Do you have the time taken in the status bar?
This feature is Particularly important if the user runs a semi-long task (e.g.30 seconds) once a day. Only at the end of the long process can they know the particular amount of time, if the time taken dialog is shown after the finish. If the status bar contains the time taken and the progress bar contains the progress percentage, they can evaluate how long it will take according to the time taken and percentage. Then they can switch to other work or go get a cup of coffee.
Also a developer, you can use it to know if a piece of code you have modified has increased the performance of the task or hindered it.
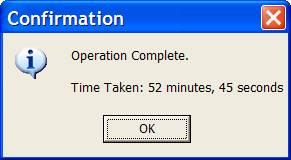
❌ Figure: Bad example - popup dialog at the end of a long process
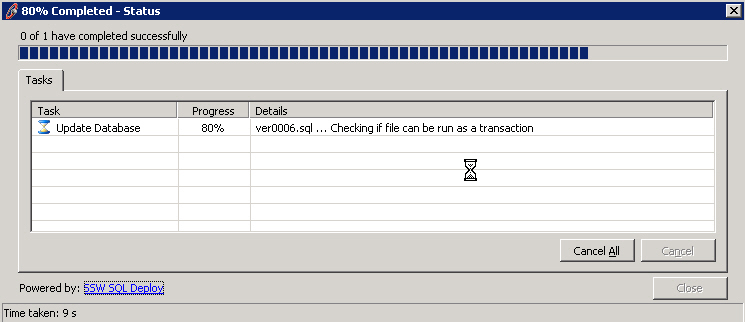
✅ Figure: Good example - show time taken in the status bar
Do you import namespaces and shorten the references?
You should import namespaces and shorten the references.
System.Text.StringBuilder myStringBuilder = new System.Text.StringBuilder();❌ Figure: Figure: Bad code - Long reference to object name
using System.Text;......StringBuilder myStringBuilder = new StringBuilder();✅ Figure: Figure: Good code - Import the namespace and remove the repeated System.Text reference
If you have ReSharper installed, you can let ReSharper take care of this for you:
Figure: Right click and select "Reformat Code..."
Figure: Make sure "Shorten references" is checked and click "Reformat"
Do you initialize variables outside of the try block?
You should initialize variables outside of the try block.
Cursor cur;try {// ...cur = Cursor.Current; //Bad Code - initializing the variable inside the try blockCursor.Current = Cursors.WaitCursor;// ...} finally {Cursor.Current = cur;}❌ Figure: Bad Example: Because of the initializing code inside the try block. If it failed on this line then you will get a NullReferenceException in Finally
Cursor cur = Cursor.Current; //Good Code - initializing the variable outside the try blocktry {// ...Cursor.Current = Cursors.WaitCursor;// ...} finally {Cursor.Current = cur;}✅ Figure: Good Example : Because the initializing code is outside the try block
Do you know that Enum types should not be suffixed with the word "Enum"?
This is against the .NET Object Naming Conventions and inconsistent with the framework.
Public Enum ProjectLanguageEnum CSharp VisualBasic End Enum❌ Figure: Bad example - Enum type is suffixed with the word "Enum"
Public Enum ProjectLanguage CSharp VisualBasic End Enum✅ Figure: Good example - Enum type is not suffixed with the word "Enum"
We have a program called SSW Code Auditor to check for this rule.
Do you know how to use Connection Strings?
There are 2 type of connection strings. The first contains only address type information without authorization secrets. These can use all of the simpler methods of storing configuration as none of this data is secret.
Option 1 - Using Azure Managed Identities (Recommended)
When deploying an Azure hosted application we can use Azure Managed Identities to avoid having to include a password or key inside our connection string. This means we really just need to keep the address or url to the service in our application configuration. Because our application has a Managed Identity, this can be treated in the same way as a user's Azure AD identity and specific roles can be assigned to grant the application access to required services.
This is the preferred method wherever possible, because it eliminates the need for any secrets to be stored. The other advantage is that for many services the level of access control available using Managed Identities is much more granular making it much easier to follow the Principle of Least Privilege.
Option 2 - Connection Strings with passwords or keys
If you have to use some sort of secret or key to login to the service being referenced, then some thought needs to be given to how those secrets can be secured. Take a look at Do you store your secrets securely to learn how to keep your secrets secure.
Example - Integrating Azure Key Vault into your ASP.NET Core application
In .NET 5 we can use Azure Key Vault to securely store our connection strings away from prying eyes.
Azure Key Vault is great for keeping your secrets secret because you can control access to the vault via Access Policies. The access policies allows you to add Users and Applications with customized permissions. Make sure you enable the System assigned identity for your App Service, this is required for adding it to Key Vault via Access Policies.
You can integrate Key Vault directly into your ASP.NET Core application configuration. This allows you to access Key Vault secrets via
IConfiguration.public static IHostBuilder CreateHostBuilder(string[] args) =>Host.CreateDefaultBuilder(args).ConfigureWebHostDefaults(webBuilder =>{webBuilder.UseStartup<Startup>().ConfigureAppConfiguration((context, config) =>{// To run the "Production" app locally, modify your launchSettings.json file// -> set ASPNETCORE_ENVIRONMENT value as "Production"if (context.HostingEnvironment.IsProduction()){IConfigurationRoot builtConfig = config.Build();// ATTENTION://// If running the app from your local dev machine (not in Azure AppService),// -> use the AzureCliCredential provider.// -> This means you have to log in locally via `az login` before running the app on your local machine.//// If running the app from Azure AppService// -> use the DefaultAzureCredential provider//TokenCredential cred = context.HostingEnvironment.IsAzureAppService() ?new DefaultAzureCredential(false) : new AzureCliCredential();var keyvaultUri = new Uri($"https://{builtConfig["KeyVaultName"]}.vault.azure.net/");var secretClient = new SecretClient(keyvaultUri, cred);config.AddAzureKeyVault(secretClient, new KeyVaultSecretManager());}});});✅ Figure: Good example - For a complete example, refer to this [sample application](https://github.com/william-liebenberg/keyvault-example)
Tip: You can detect if your application is running on your local machine or on an Azure AppService by looking for the
WEBSITE_SITE_NAMEenvironment variable. If null or empty, then you are NOT running on an Azure AppService.public static class IWebHostEnvironmentExtensions{public static bool IsAzureAppService(this IWebHostEnvironment env){var websiteName = Environment.GetEnvironmentVariable("WEBSITE_SITE_NAME");return string.IsNullOrEmpty(websiteName) is not true;}}Setting up your Key Vault correctly
In order to access the secrets in Key Vault, you (as User) or an Application must have been granted permission via a Key Vault Access Policy.
Applications require at least the LIST and GET permissions, otherwise the Key Vault integration will fail to retrieve secrets.
Figure: Key Vault Access Policies - Setting permissions for Applications and/or Users
Azure Key Vault and App Services can easily trust each other by making use of System assigned Managed Identities. Azure takes care of all the complicated logic behind the scenes for these two services to communicate with each other - reducing the complexity for application developers.
So, make sure that your Azure App Service has the System assigned identity enabled.
Once enabled, you can create a Key Vault Access policy to give your App Service permission to retrieve secrets from the Key Vault.
Figure: Enabling the System assigned identity for your App Service - this is required for adding it to Key Vault via Access Policies
Adding secrets into Key Vault is easy.
- Create a new secret by clicking on the Generate/Import button
- Provide the name
- Provide the secret value
- Click Create
Figure: Creating the SqlConnectionString secret in Key Vault.
Figure: SqlConnectionString stored in Key Vault
Note: The ApplicationSecrets section is indicated by "ApplicationSecrets--" instead of "ApplicationSecrets:".
As a result of storing secrets in Key Vault, your Azure App Service configuration (app settings) will be nice and clean. You should not see any fields that contain passwords or keys. Only basic configuration values.
Figure: Your WebApp Configuration - No passwords or secrets, just a name of the Key vault that it needs to access
Video: Watch SSW's William Liebenberg explain Connection Strings and Key Vault in more detail (8 min)History of Connection Strings
In .NET 1.1 we used to store our connection string in a configuration file like this:
<configuration><appSettings><add key="ConnectionString" value ="integrated security=true;data source=(local);initial catalog=Northwind"/></appSettings></configuration>...and access this connection string in code like this:
SqlConnection sqlConn =new SqlConnection(System.Configuration.ConfigurationSettings.AppSettings["ConnectionString"]);❌ Figure: Historical example - Old ASP.NET 1.1 way, untyped and prone to error
In .NET 2.0 we used strongly typed settings classes:
Step 1: Setup your settings in your common project. E.g. Northwind.Common
Figure: Settings in Project Properties
Step 2: Open up the generated App.config under your common project. E.g. Northwind.Common/App.config
Step 3:
Copy the content into your entry applications app.config. E.g. Northwind.WindowsUI/App.configThe new setting has been updated to app.config automatically in .NET 2.0<configuration><connectionStrings><add name="Common.Properties.Settings.NorthwindConnectionString"connectionString="Data Source=(local);Initial Catalog=Northwind;Integrated Security=True"providerName="System.Data.SqlClient" /></connectionStrings></configuration>...then you can access the connection string like this in C#:
SqlConnection sqlConn =new SqlConnection(Common.Properties.Settings.Default.NorthwindConnectionString);❌ Figure: Historical example - Access our connection string by strongly typed generated settings class...this is no longer the best way to do it
Do you know what to do with a work around?
<introEmbed body={<> If you have to use a workaround you should always comment your code. In your code add comments with: </>} /> 1. The pain - In the code add a URL to the existing resource you are following e.g. a blog post 2. The potential solution - Search for a suggestion on the product website. If there isn't one, create a suggestion to the product team that points to the resource. e.g. on <https://uservoice.com/> or <https://bettersoftwaresuggestions.com/> <asideEmbed variant="greybox" body={<> "This is a workaround as per the suggestion \[URL]" </>} figureEmbed={{ preset: "default", figure: 'Always add a URL to the suggestion that you are compensating for', shouldDisplay: true }} /> ### Exercise: Understand commenting You have just added a grid that auto updates, but you need to disable all the timers when you click the edit button. You have found an article on Code Project (<http://www.codeproject.com/Articles/39194/Disable-a-timer-at-every-level-of-your-ASP-NET-con.aspx>) and you have added the work around. Now what do you do? ```cs protected override void OnPreLoad(EventArgs e) { //Fix for pages that allow edit in grids this.Controls.ForEach(c => { if (c is System.Web.UI.Timer) { c.Enabled = false; } }); base.OnPreLoad(e); } ``` **Figure: Work around code in the Page Render looks good. The code is done, something is missing**Do you know when to use named parameters?
Named parameters have always been there for VB developers and in C# 4.0, C# developers finally get this feature.
You should use named parameters under these scenarios:
- When there are 4 or more parameters
- When you make use of optional parameters
- If it makes more sense to order the parameters a certain way
Do you know where to store your application's files?
Although many have differing opinions on this matter, Windows applications have standard storage locations for their files, whether they're settings or user data. Some will disagree with those standards, but it's safe to say that following it regardless will give users a more consistent and straightforward computing experience.
The following grid shows where application files should be placed:

Further Information
- The System.Environment class provides the most general way of retrieving those paths
- The Application class lives in the System.Windows.Form namespace, which indicates it should only be used for WinForm applications. Other types of applications such as Console and WebForm applications use their corresponding utility classes
Microsoft's write-up on this subject can be found at Microsoft API and reference catalog.
Do you name your events properly?
Events should end in "ing" or "ed".
public event Action< connectioninformation > ConnectionProblem;❌ Figure: Bad example
public event Action< connectioninformation > ConnectionProblemDetected;✅ Figure: Good example
Do you pre-format your time strings before using TimeSpan.Parse()?
TimeSpan.Parse() constructs a Timespan from a time indicated by a specified string. The acceptable parameters for this function are in the format "d.hh:mm" where "d" is the number of days (it is optional), "hh" is hours and is between 0 and 23 and "mm" is minutes and is between 0 and 59. If you try to pass, as a parameter, as a string such as "45:30" (meaning 45 hours and 30 minutes), TimeSpan.Parse() function will crash. (The exact exception received is: "System.OverflowException: TimeSpan overflowed because duration is too long".) Therefore it is recommended that you should always pre-parse the time string before passing it to the "TimeSpan.Parse()" function.
This pre-parsing is done by the FormatTimeSpanString( ) function. This function will format the input string correctly. Therefore, a time string of value "45:30" will be converted to "1.21:30" (meaning 1 day, 21 hours and 30 minutes). This format is perfectly acceptable for TimeSpan.Parse() function and it will not crash.
ts = TimeSpan.Parse(cboMyComboBox.Text)❌ Figure: Figure: Bad example - A value greater than 24hours will crash eg. 45:30
ts = TimeSpan.Parse(FormatTimeSpanString(cboMyComboBox.Text))✅ Figure: Figure: Good example - Using a wrapper method to pre-parse the string containing the TimeSpan value.
We have a program called SSW Code Auditor to check for this rule.
Do you know not to put Exit Sub before End Sub? (VB)
Do not put "Exit Sub" statements before the "End Sub". The function will end on "End Sub". "Exit Sub" is serving no real purpose here.
Private Sub SomeSubroutine()'Your code here....Exit Sub ' Bad code - Writing Exit Sub before End Sub.End Sub❌ Figure: Bad example
Private Sub SomeOtherSubroutine()'Your code here....End Sub✅ Figure: Good example
We have a program called SSW Code Auditor to check for this rule.
Do you put optional parameters at the end?
Optional parameters should be placed at the end of the method signature as optional ones tend to be less important. You should put the important parameters first.
public void SaveUserProfile([Optional] string username,[Optional] string password,string firstName,string lastName,[Optional] DateTime? birthDate) {}❌ Figure: Figure: Bad example - Username and Password are optional and first - they are less important than firstName and lastName and should be put at the end
public void SaveUserProfile(string firstName,string lastName,[Optional] string username,[Optional] string password,[Optional] DateTime? birthDate) {}✅ Figure: Figure: Good example - All the optional parameters are the end
Note: When using optional parameters, please be sure to use named para meters
Do you refer to form controls directly?
When programming in form based environments one thing to remember is not to refer to form controls directly. The correct way is to pass the controls values that you need through parameters.
There are a number of benefits for doing this:
- Debugging is simpler because all your parameters are in one place
- If for some reason you need to change the control's name then you only have to change it in one place
- The fact that nothing in your function is dependant on outside controls means you could very easily reuse your code in other areas without too many problems re-connecting the parameters being passed in
It's a correct method of programming.
Private Sub Command0_Click()CreateScheduleEnd SubSub CreateSchedule()Dim dteDateStart As DateDim dteDateEnd As DatedteDateStart = Format(Me.ctlDateStart,"dd/mm/yyyy") 'Bad Code - refering the form control directlydteDateEnd = Format(Me.ctlDateEnd, "dd/mm/yyyy").....processing codeEnd Sub❌ Figure: Bad example
Private Sub Command0_Click()CreateSchedule(ctlDateStart, ctlDateEnd)End SubSub CreateSchedule(pdteDateStart As Date, pdteDateEnd As Date)Dim dteDateStart As DateDim dteDateEnd As DatedteDateStart = Format(pdteDateStart, "dd/mm/yyyy") 'Good Code - refering the parameter directlydteDateEnd = Format(pdteDateEnd, "dd/mm/yyyy")&....processing codeEnd Sub✅ Figure: Good example
Do you know how to format your MessageBox code?
You should always write each parameter of MessageBox in a separate line. So it will be more clear to read in the code. Format your message text in code as you want to see on the screen.
Private Sub ShowMyMessage()MessageBox.Show("Areyou sure you want to delete the team project """ + strProjectName+ """?" + Environment.NewLine + Environment.NewLine + "Warning:Deleting a team project cannot be undone.", strProductName + "" + strVersion(), MessageBoxButtons.YesNo, MessageBoxIcon.Warning, MessageBoxDefaultButton.Button2)❌ Figure: Figure: Bad example of MessageBox code format
Private Sub ShowMyMessage()MessageBox.Show( _"Are you sure you want to delete the team project """ + strProjectName + """?"_ + Environment.NewLine _ +Environment.NewLine _ +"Warning: Deleting a team project cannot be undone.", _strProductName + " " + strVersion(), _MessageBoxButtons.YesNo, _MessageBoxIcon.Warning, _MessageBoxDefaultButton.Button2)End Sub✅ Figure: Figure: Good example of MessageBox code format
Do you reference websites when you implement something you found on Google?
If you end up using someone else's code, or even idea, that you found online, make sure you add a reference to this in your source code. There is a good chance that you or your team will revisit the website. And of course, it never hurts to tip your hat, to thank other coders.
private void HideToSystemTray(){// Hide the windows form in the system trayif (FormWindowState.Minimized == WindowState){Hide();}}❌ Figure: Bad example - The website where the solution was found IS NOT referenced in the comments
private void HideToSystemTray(){// Hide the windows form in the system tray// I found this solution at http://www.developer.com/net/csharp/article.php/3336751if (FormWindowState.Minimized == WindowState){Hide();}}✅ Figure: Good example - The website where the solution was found is referenced in the comments
Do you store Application-Level Settings in your database rather than configuration files when possible?
For database applications, it is best to keep application-level values (apart from connection strings) from this in the database rather than in the web.config. There are some merits as following:
- It can be updated easily with normal SQL e.g. Rolling over the current setting to a new value.
- It can be used in joins and in other queries easily without the need to pass in parameters.
- It can be used to update settings and affect the other applications based on the same database.
Do you suffix unit test classes with "Tests"?
Unit test classes should be suffixed with the word "Tests" for better coding readability.
[TestFixture] public class SqlValidatorReportTest { }❌ Figure: Bad example - Unit test class is not suffixed with "Tests"
[TestFixture] public class HtmlDocumentTests { }✅ Figure: Good example - Unit test class is suffixed with "Tests"
We have a program called SSW Code Auditor to check for this rule.
Do you use a helper extension method to raise events?
Enter Intro Text
Instead of:
private void RaiseUpdateOnExistingLotReceived() {if (ExistingLotUpdated != null) {ExistingLotUpdated();}}...use this event extension method:
public static void Raise<t>(this EventHandler<t> @event,object sender,T args) where T : EventArgs {var temp = @event;if (temp != null) {temp(sender, args);}}public static void Raise(this Action @event) {var temp = @event;if (temp != null) {temp();}}That means that instead of calling:
RaiseExistingLotUpdated();...you can do:
ExistingLotUpdated.Raise();Less code = less code to maintain = less code to be blamed for ;)
Do you use a regular expression to validate an email address?
A regex is the best way to verify an email address.
public bool IsValidEmail(string email){// Return true if it is in valid email format.if (email.IndexOf("@") <= 0) return false;if (email.EndWith("@")) return false;if (email.IndexOf(".") <= 0) return false;if ( ...}❌ Figure: Figure: Bad example of verify email address
public bool IsValidEmail(string email){// Return true if it is in valid email format.return System.Text.RegularExpressions.Regex.IsMatch( email,@"^([\w-\.]+)@(([[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.)|(([\w-]+\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\]?)$";}✅ Figure: Figure: Good example of verify email address
Do you use a regular expression to validate an URL?
A regex is the best way to verify an URI.
public bool IsValidUri(string uri){try{Uri testUri = new Uri(uri);return true;}catch (UriFormatException ex){return false;}}❌ Figure: Figure: Bad example of verifying URI
public bool IsValidUri(string uri){// Return true if it is in valid Uri format.return System.Text.RegularExpressions.Regex.IsMatch( uri,@"^(http|ftp|https)://([^\/][\w-/:]+\.?)+([\w- ./?/:/;/\%&=]+)?(/[\w- ./?/:/;/\%&=]*)?");}✅ Figure: Figure: Good example of verifying URI
You should have unit tests for it, see our Rules to Better Unit Tests for more information.
Do you use Enums instead of hard coded strings?
Use Enums instead of hard-coded strings, it makes your code lot cleaner and is really easy to manage .
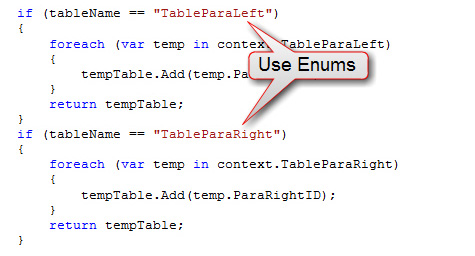
❌ Figure: Bad example - "Hard- coded string" works, but is a bad idea
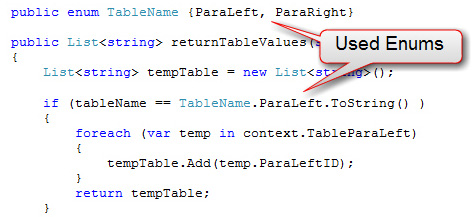
✅ Figure: Good example - Used Enums, looks good and is easy to manage
Do you use Environment.NewLine to make a new line in your string?
When you need to create a new line in your string, make sure you use Environment.NewLine, and then literally begin typing your code on a new line for readability purposes.
string strExample = "This is a very long string that is \r\n not properly implementing a new line.";❌ Figure: Bad example - The string has implemented a manual carriage return line feed pair ` `
string strExample = "This is a very long string that is " + Environment.NewLine +" properly implementing a new line.";✅ Figure: OK example - The new line is created with Enviroment.NewLine (but strings are immutable)
var example = new StringBuilder();example.AppendLine("This is a very long string that is ");example.Append(" properly implementing a new line.");✅ Figure: Good example - The new line is created by the StringBuilder and has better memory utilisation
Do you use good code over backward compatibility?
Supporting old operating systems and old versions means you have more (and often messy) code, with lots of if or switch statements. This might be OK for you because you wrote the code, but down the track when someone else is maintaining it, then there is more time/expense needed.
When you realize there is a better way to do something, then you will change it, clean code should be the goal, however, because this affects old users, and changing interfaces at every whim also means an expense for all the apps that break, the decision isn't so easy to make.
Our views on backward compatibility start with asking these questions:
- Question 1: How many apps are we going to break externally?
- Question 2: How many apps are we going to break internally?
- Question 3: What is the cost of providing backward compatibility and repairing (and test) all the broken apps?
Let's look at an example:
If we change the URL of this public Web Service, we'd have to answer the questions as follows:
- Answer 1: Externally - Don't know, we have some leads: We can look at web stats and get an idea. If an IP address enters our website at this point, it tells us that possibly an application is using it and the user isn't just following the links.
- Answer 2: Website samples + Adams code demo
- Answer 3: Can add a redirect or change the page to output a warning Old URL. Please see www.ssw.com.au/ PostCodeWebService for new URL
Because we know that not many external clients use this example, we decide to remove the old web service after some time.
Just to be friendly, we would send an email for the first month, and then another email in the second month. After that, just emit "This is deprecated (old)." We'll also need to update the UDDI so people don't keep coming to our old address.
We probably all prefer working on new features, rather than supporting old code, but it’s still a core part of the job. If your answer to question 3 scares you, it might be time to consider a backward compatibility warning.
From:JohnCc:SSWAllBcc:ZZZSubject:Changing LookOut settingsHi All,
The stored procedure procLookOutClientSelect (currently used only by LookOut any version prior to 10) is being renamed to procSSWLookOutClientIDSelect. The old stored procedure will be removed within 1 month.
You can change your settings either by:
- Going to LookOut Options -> Database tab and select the new stored procedure
- Upgrading to SSW LookOut version 10.0 which will be released later today
✅ Figure: Good Example - Email as a backward compatibility warning
Do you use Public/Protected Properties instead of Public/Protected Fields?
Public/Protected properties have a number of advantages over public/protected fields:
- Data validation Data validation can be performed in the get/set accessors of a public property. This is especially important when working with the Visual Studio .NET Designer.
- Increased flexibility Properties conceal the data storage mechanism from the user, resulting in less broken code when the class is upgraded. Properties are a recommended object-oriented practice for this reason.
- Compatibility with data binding You can only bind to a public property, not a field.
- Minimal performance overhead The performance overhead for public properties is trivial. In some situations, public fields can actually have inferior performance to public properties.
public int Count;❌ Figure: Figure: Bad code - Variable declared as a Field
public int Count{get{return _count;}set{_count = value;}}✅ Figure: Figure: Good code - Variable declared as a Property
We agree that the syntax is tedious and think Microsoft should improve this.
Do you use resource file to store all the messages and globlal strings?
Storing all the messages and global strings in one place will make it easy to manage them and to keep the applications in the same style.
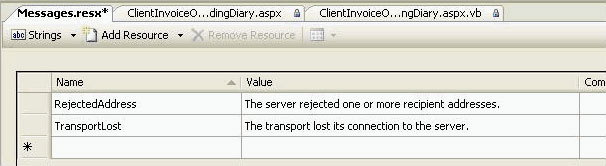 Catch(SqlNullValueException sqlex){Response.Write("The value cannot be null.");}
Catch(SqlNullValueException sqlex){Response.Write("The value cannot be null.");}❌ Figure: Bad example - If you want to change the message, it will cost you lots of time to investigate every try-catch block
Catch(SqlNullValueException sqlex){Response.Write(GetGlobalResourceObject("Messages", "SqlValueNotNull"));}😐 Figure: OK example - Better than the hard code, but still wordy
Catch(SqlNullValueException sqlex){Response.Write(Resources.Messages.SqlValueNotNull); 'Good Code - storing message in resource file.}✅ Figure: Good example
Do you use resource file to store messages?
All messages are stored in one central place so it's easy to reuse. Furthermore, it is strongly typed - easy to type with IntelliSense in Visual Studio.
Module Startup Dim HelloWorld As String = "Hello World!" Sub Main() Console.Write(HelloWorld)Console.Read() End Sub End Module❌ Figure: Bad example of a constant message
::: good\
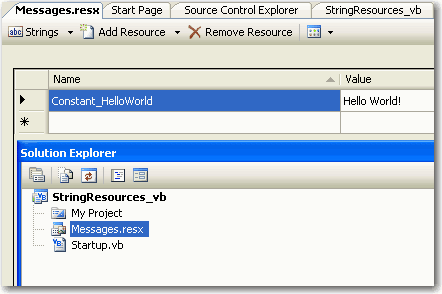
Figure: Saving constant message in Resource
:::
Module Startup Sub Main() Console.Write(My.Resources.Messages.Constant_HelloWorld) Console.Read() End Sub End Module✅ Figure: Good example of a constant message
Do you use String.Empty instead of ""?
Since .NET 5+, the choice between using String.Empty and "" is a stylistic decision for the team. In .NET Framework, "" is less efficient than String.Empty from a memory perspective which can result in better performance due to faster garbage collection.
From the team that worked on performance in .NET: String.Empty vs "" in modern .NET language
public string myString{get{return ;}}❌ Figure: Figure: Bad code if used in .NET Framework. Low performance
public string myString{get{return string.Empty;}}✅ Figure: Figure: Good code if used in .NET Framework. Higher performance
We have a program called SSW Code Auditor to check for this rule.
Do you use "using" declaration instead of use explicitly "dispose"?
Don't explicitly use "dispose" to close objects and dispose of them, the "using" statement will do all of them for you. It is another awesome tool that helps reduce coding effort and possible issues.
static int WriteLinesToFile(IEnumerable<string> lines){// We must declare the variable outside of the using block// so that it is in scope to be returned.int skippedLines = 0;var file = new System.IO.StreamWriter("WriteLines2.txt")foreach (string line in lines){if (!line.Contains("Second")){file.WriteLine(line);}else{skippedLines++;}}file.Dispose();return skippedLines;}❌ Figure: Figure: Bad example of dispose of resources
static int WriteLinesToFile(IEnumerable<string> lines){// We must declare the variable outside of the using block// so that it is in scope to be returned.int skippedLines = 0;using (var file = new System.IO.StreamWriter("WriteLines2.txt")){foreach (string line in lines){if (!line.Contains("Second")){file.WriteLine(line);}else{skippedLines++;}}} // file is disposed herereturn skippedLines;}❌ Figure: Figure: Bad example of dispose of resources
static int WriteLinesToFile(IEnumerable<string> lines){using var file = new System.IO.StreamWriter("WriteLines2.txt");// Notice how we declare skippedLines after the using statement.int skippedLines = 0;foreach (string line in lines){if (!line.Contains("Second")){file.WriteLine(line);}else{skippedLines++;}}// Notice how skippedLines is in scope here.return skippedLines;// file is disposed here}✅ Figure: Figure: Good example of dispose of resources, using c# 8.0 using declaration
Tip: Did you know it is not recommended to dispose HttpClient?
One last note is regarding disposing of HttpClient. Yes, HTTPClient does implement IDisposable, however, I do not recommend creating a HttpClient inside a Using block to make a single request. When HttpClient is disposed it causes the underlying connection to be closed also. This means the next request has to re-open that connection. You should try and re-use your HttpClient instances. If the server really does not want you holding open it’s connection then it will send a header to request the connection be closed.
Do you warn users before starting a long process?
When your application is about to start a long process (more than 30 seconds) it should first show a warning message to let the user know approximately how long it will take.
You will need to have 2 things:
- A table to record processes containing the following fields:
- ALogRecord (DateCreated, FunctionName, EmpUpdated, ComputerName, ActiveForm, ActiveControl, SystemsResources, ConventionalMemory, FormsCount, TimeStart, TimeEnd, TimeTaken, RecordsProcessed, Avg, Note, RowGuide, SSWTimeStamp)
- A function to change the number of seconds lapsed to words - see the "1 minute, 9 seconds" in the above messagebox - this requires a
SecondsToWords()function shown
✅ Figure: Good example - Code Auditor message warning this is a long process
DRY - Do you wrap the same logic in a method instead of writing it repeatedly whenever it's used?
Is your code DRY? Any logic that is used more than once, should be encapsulated in a method, and the method called wherever it is needed.
This will reduce redundancy, decrease maintenance effort, improve efficiency and reusability, and make the code more clear to read.
DRY, which stands for ‘don’t repeat yourself,’ is a principle of software development that aims at reducing the repetition of patterns and code duplication in favor of abstractions and avoiding redundancy.
public class WarningEmail{//...public void SendWarningEmail(string pFrom, string pTo, string pCC, string pUser, string pPwd, string pDomain){//...MailMessage sMessage = new MailMessage();sMessage.From = new MailAddress(pFrom);sMessage.To.Add(pTo);sMessage.CC.Add(pCC);sMessage.Subject = "This is a Warning";sMessage.Body = GetWarning();SmtpClient sSmtpClient = new SmtpClient();sSmtpClient.Credentials = new NetworkCredential(pUser, pPwd, pDomain);sSmtpClient.Send(sMessage);//...}}public class ErrorEmail{public void SendErrorEmail(string pFrom, string pTo, string pCC, string pUser, string pPwd, string pDomain){//...MailMessage sMessage = new MailMessage();sMessage.From = new MailAddress(pFrom);sMessage.To.Add(pTo);sMessage.CC.Add(pCC);sMessage.Subject = "This is a Error";sMessage.Body = GetError();SmtpClient sSmtpClient = new SmtpClient();sSmtpClient.Credentials = new NetworkCredential(pUser, pPwd, pDomain);sSmtpClient.Send(sMessage);//...}}❌ Figure: Bad example - Write the same logic repeatedly
public class WarningEmail{//...public void SendWarningEmail(string pFrom, string pTo, string pCC, string pUser, string pPwd, string pDomain){//...EmailHelper.SendEmail(pFrom, pTo, pCC, "This is a Warning", GetWarning(), pUser, pPwd, pDomain);//...}}public class ErrorEmail{public void SendErrorEmail(string pFrom, string pTo, string pCC, string pUser, string pPwd, string pDomain){//...EmailHelper.SendEmail(pFrom, pTo, pCC, "This is an Error", GetError(), pUser, pPwd, pDomain);//...}}public class EmailHelper{public static void SendEmail(string pFrom, string pTo, string pCC, string pSubject, string pBody, string pUser, string pPwd, string pDomain){MailMessage sMessage = new MailMessage();sMessage.From = new MailAddress(pFrom);sMessage.To.Add(pTo);sMessage.CC.Add(pCC);sMessage.Subject = pSubject;sMessage.Body = pBody;SmtpClient sSmtpClient = new SmtpClient();sSmtpClient.Credentials = new NetworkCredential(pUser, pPwd, pDomain);sSmtpClient.Send(sMessage);}}✅ Figure: Good example - Put the same logic in a method and make it reusable
Do you know the difference between a 'smart' and a 'clever' developer?
<introEmbed body={<> When we first start out as a developer, we want to show the world what we can do by creating complex solutions. As we gain experience, we learn to show our worth by creating simple solutions. > Developers are like a fine wine, they get better with age. </>} /> Lets take this piece of code as an example: ```html <span className="text-xl"> { targetedDays === 0 ? "Today" : targetedDays === -1 ? "Yesterday" : targetedDays === 1 ? "Tomorrow" : moment().add(targetedDays, 'days').format("dddd D MMMM YYYY") } </span> ``` One liner! Nailed it 🥳 Pity the next developer who has to decipher what is going on! The [cognitive load](https://en.wikipedia.org/wiki/Cognitive_load) here is really high! and the the maintainability, is really low. What is the first thing you are going to need to do if this piece of code start behaving poorly? Now lets take the following reformatted code example: ```js const getTargetedDayAsText = (targetedDays) => { if (targetedDays === -1) { return "Yesterday"; } elseif (targetedDays === 0) { return "Today"; } elseif (targetedDays === 1) { return "Tomorrow"; } else { let days = moment().add(targetedDays, 'days'); let formatted = days.format("dddd D MMMM YYYY"); return formatted; } } <span className="text-xl"> {getTargetedDayAsText(targetedDays)} </span> ``` Now this is nowhere near as terse, but anyone looking at it is able to quickly determine what is going on. And anyone who has to investigate any issue with the code is going to be able to step through and debug this without any issues. This above is not an overly complicated example but now imagine something like this [example](https://learn.microsoft.com/en-us/archive/blogs/lukeh/taking-linq-to-objects-to-extremes-a-fully-linqified-raytracer?WT.mc_id=AI-MVP-33518) ```js var pixelsQuery = from y in Enumerable.Range(0, screenHeight) let recenterY = -(y - (screenHeight / 2.0)) / (2.0 * screenHeight) select from x in Enumerable.Range(0, screenWidth) let recenterX = (x - (screenWidth / 2.0)) / (2.0 * screenWidth) let point = Vector.Norm(Vector.Plus(scene.Camera.Forward, Vector.Plus(Vector.Times(recenterX, scene.Camera.Right), Vector.Times(recenterY, scene.Camera.Up)))) let ray = new Ray() { Start = scene.Camera.Pos, Dir = point } let computeTraceRay = (Func<Func<TraceRayArgs, Color>, Func<TraceRayArgs, Color>>) (f => traceRayArgs => (from isect in from thing in traceRayArgs.Scene.Things select thing.Intersect(traceRayArgs.Ray) where isect != null orderby isect.Dist let d = isect.Ray.Dir let pos = Vector.Plus(Vector.Times(isect.Dist, isect.Ray.Dir), isect.Ray.Start) let normal = isect.Thing.Normal(pos) let reflectDir = Vector.Minus(d, Vector.Times(2 * Vector.Dot(normal, d), normal)) let naturalColors = from light in traceRayArgs.Scene.Lights let ldis = Vector.Minus(light.Pos, pos) let livec = Vector.Norm(ldis) let testRay = new Ray() { Start = pos, Dir = livec } let testIsects = from inter in from thing in traceRayArgs.Scene.Things select thing.Intersect(testRay) where inter != null orderby inter.Dist select inter let testIsect = testIsects.FirstOrDefault() let neatIsect = testIsect == null ? 0 : testIsect.Dist let isInShadow = !((neatIsect > Vector.Mag(ldis)) || (neatIsect == 0)) where !isInShadow let illum = Vector.Dot(livec, normal) let lcolor = illum > 0 ? Color.Times(illum, light.Color) : Color.Make(0, 0, 0) let specular = Vector.Dot(livec, Vector.Norm(reflectDir)) let scolor = specular > 0 ? Color.Times(Math.Pow(specular, isect.Thing.Surface.Roughness), light.Color) : Color.Make(0, 0, 0) select Color.Plus(Color.Times(isect.Thing.Surface.Diffuse(pos), lcolor), Color.Times(isect.Thing.Surface.Specular(pos), scolor)) let reflectPos = Vector.Plus(pos, Vector.Times(.001, reflectDir)) let reflectColor = traceRayArgs.Depth >= MaxDepth ? Color.Make(.5, .5, .5) : Color.Times(isect.Thing.Surface.Reflect(reflectPos), f(new TraceRayArgs(new Ray() { Start = reflectPos, Dir = reflectDir }, traceRayArgs.Scene, traceRayArgs.Depth + 1))) select naturalColors.Aggregate(reflectColor, (color, natColor) => Color.Plus(color, natColor)) ).DefaultIfEmpty(Color.Background).First()) let traceRay = Y(computeTraceRay) select new { X = x, Y = y, Color = traceRay(new TraceRayArgs(ray, scene, 0)) }; foreach (var row in pixelsQuery) foreach (var pixel in row) setPixel(pixel.X, pixel.Y, pixel.Color.ToDrawingColor()); ``` This was fortunately just someone's exercise in proving that they could and happily states > Just because you can, doesn't mean you should! So what are some of the things that developers learn over time that takes them from being a Clever developer to being a Smart developer? ### Avoiding problems Clever developers fix a problem where Smart Developers stop a problem from happening. Lets say you receive a PBI saying that XYZ method is always returning a value 0.001 more than it should. #### Smart Developer Identifies that some incoming data is always out and results in the small rounding issue. ```js return value - 0.001; ``` #### Clever Developer Identifies that a method downstream is rounding to 2 decimal places and removes this. ### Understanding the whole before they start Code costs money, not just to create but also to maintain. <imageEmbed alt="Image" size="large" showBorder={false} figureEmbed={{ preset: "default", figure: 'Clever developer coding away and resolving PBI\'s', shouldDisplay: true }} src="/uploads/rules/do-you-know-the-difference-between-a-clever-and-a-smart-developer/https://media1.giphy.com/media/IhO6ksgdk31JxbbFLA/200w.gif?cid=82a1493bmbpukqu53l1t49epgeet5ftpueaao9zhf2a6szbn&rid=200w.gif&ct=g" />Use Enum Constants instead of Magic numbers?
Using "Magic numbers" in your code makes it confusing and really hard to maintain.
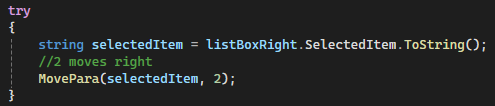
❌ Figure: Bad example - "Magic Number" works, but is a bad idea
✅ Figure: Good example - Add Enum

✅ Figure: Good example - No Magic Number, looks good and is easy to manage
Do you avoid using magic string when referencing property/variable names
Hard coded strings when referencing property and variable names can be problematic as your codebase evolves, and can make your code brittle.
(if customer.Address.ZipCode == null) throw new ArgumentNullException("ZipCode");❌ Figure: Figure: Bad Example - Hardcoding a reference to a property
(if customer.Address.ZipCode == null) throw new ArgumentNullException(nameof(customer.Address.ZipCode));✅ Figure: Figure: Good Example - Using nameof() operator to avoid hardcoded strings
Do you use null condition operators when getting values from objects
Null-conditional operators - makes checking for null as easy as inserting a single question mark. The Null-conditional operators feature boils down all of the previously laborious clunky code into a single question mark.
int length = customer != null && customer.name != null ? customer.name.length : 0;❌ Figure: Figure: Bad example - Verbose and complex code checking for nulls
int length = customers?.name?.length ?? 0;✅ Figure: Figure: Good example - Robust and easier to read code
Do you use string interpolation when formatting strings
String Interpolation - greatly reduces the amount of boilerplate code required when working with strings Formatting strings on the fly was previously a task which required a stack of boilerplate code
var s = String.Format("Profit is ${0} this year", p.TotalEarnings - p.Totalcost);❌ Figure: Figure: Bad Example - Using String.Format() makes the code difficult to read
var s = "Profit is ${p.TotalEarnings - p.Totalcost} this year";✅ Figure: Figure: Good Example - String Interpolation is very human readable
Do you use the new C# 7 language features to slash the amount of boilerplate code you write?
<introEmbed body={<> Up until this point, .NET developers had to write a lot of boilerplate code in order to properly format strings or check for null. This boilerplate code required a lot of work to ensure code readability and maintainability. The new C# 6 that comes with Visual Studio 2015 is a game changer that empowers devs to do more with less. These 3 features will slash the amount of boilerplate code you have to write and improve code quality: </>} /> 1. **nameof expressions** - Allows us to get the name of the type of object. Now when we throw an exception, we can use the name of expressions feature to create robust code, which is more resistant to common mistakes when refactoring. This is achieved by reducing the amount of hard coding. As you can see, when in the past you would have to write the following code: ```csharp (if customer.Address.ZipCode == null) throw new ArgumentNullException("ZipCode"); ``` <figureEmbed figureEmbed={{ preset: "badExample", figure: 'Figure: Bad example - Amount of boiler plate code for a simple task', shouldDisplay: true } } /> Now you only have write: ```csharp (if customer.Address.ZipCode == null) throw new ArgumentNullException(nameof(customer.Address.ZipCode)); ``` <figureEmbed figureEmbed={{ preset: "goodExample", figure: 'Figure: Good example - The same functionality as the Bad Example in a single line of code ::: The benefit of this change is when refactoring our code, we don\'t need to worry about searching for magic strings. Which commonly slip through the cracks and lead to confusing error messages. 2. S**tring Interpolation** - Greatly reduces the amount of boilerplate code required when working with strings Formatting strings on the fly was previously a task which required a stack of boilerplate code. In the Visual Studio 2015, we can use the smart String Interpolation feature. Not only does this feature reduce the amount of code we have to write, it also improves code readability. For example, before C# 6, we would write: ```csharp var s = String.Format("Profit is ${0} this year", p.TotalEarnings - p.Totalcost); ```', shouldDisplay: true } } /> bad Figure: Bad example - Using the string format make the code difficult to read ::: Now we are able to: ```csharp var s = "Profit is ${p.TotalEarnings - p.Totalcost} this year"; ``` <figureEmbed figureEmbed={{ preset: "goodExample", figure: 'Figure: Good example - Very human readable code', shouldDisplay: true } } /> As can be seen above by making use of the new String Interpolation feature, the understandability of your code is greatly improved. 3. **Null-conditional operators** - Makes checking for null as easy as inserting a single question mark This great new feature has had a raft of positive reactions from developers. The new Null-conditional operators feature boils down all of the previously laborious clunky code into a single question mark. For example, previously we would of had to write a chunk of code to achieve a simple task: ```csharp if(customers.Length != null) { int length = customers.Length; } else { int length = 0; } ``` <figureEmbed figureEmbed={{ preset: "badExample", figure: 'Figure: Bad example - Fragile code', shouldDisplay: true } } /> Now we are able to replace that chunk of code with a single line ```csharp int length = customers?.Length ?? 0; ``` <figureEmbed figureEmbed={{ preset: "goodExample", figure: 'Figure: Good example - Robust code', shouldDisplay: true } } /> In short, these new features will save you time, and help you write cleaner, more robust code - what's not to love?Do you declare variables when you need them?
Should you declare variables at the top of the function, or declare them when you need to use them? If you come back to your code after a few weeks and you no longer need a variable, you are quite likely to forget to delete the declaration at the top, leaving orphaned variables. Here at SSW, we believe that variables should be declared as they are needed.
Private Sub Command0_Click()Dim dteTodayDate As DateDim intRoutesPerDay As IntegerDim intRoutesToday As IntegerDim dblWorkLoadToday As DoubledblWorkLoadToday = Date.Now().....many lines of code....intRoutesPerDay = 2End Sub❌ Figure: Figure: Bad example
Private Sub Command0_Click()Dim dteTodayDate As DatedteTodayDate = Date.Now().....many lines of code....Dim intRoutesPerDay As IntegerintRoutesPerDay = 2.....continuing code....End Sub✅ Figure: Figure: Good example
Do you know that no carriage returns without line feed?
Text files created on DOS/Windows machines have different line endings than files created on Unix/Linux. DOS uses carriage return and line feed ("\r\n") as a line ending, which Unix uses just line feed ("\n").

❌ Figure: Bad example

✅ Figure: Good example
Do you document "TODO" tasks?
It's common to add a
TODOcomment to some code you're working on, either because there's more work to be done here or because you've spotted a problem that will need to be fixed later. But how do you ensure these are tracked and followed up?We add a
TODOcomment to our code when we have either identified or introduced technical debt as a way of showing other developers that there's work to be done here. It could be finishing the implementation of a feature, or it could be fixing a bug which (hypothetically) is limited in scope and therefore deprioritized. That's all well and good if another developer happens to be looking at that code and sees the comment, but if nobody looks at the code, then the problem could potentially never be fixed.public class UserService(ApplicationDbContext context) : IUserService{public async Task<UserDto> GetUserByEmailAsync(string emailAddress, CancellationToken cancellationToken = default){var dbUser = await context.Users.AsNoTracking().FirstOrDefaultAsync(u => u.Email == emailAddress, cancellationToken);// TODO: handle null user if not foundreturn new UserDto{Id = dbUser.Id,Name = dbUser.Name,Email = dbUser.Email,TenantId = dbUser.TenantId.ToString()}}}❌ Figure: Bad example - There is problematic code here, and while the comment is useful as it immediately alerts developers to the problem, but it is not tracked anywhere
Just like with any other technical debt, it's critical to ensure that it is captured on the backlog. When you add a
TODOin your code, it should always be accompanied by a link to the PBI.public class UserService(ApplicationDbContext context) : IUserService{public async Task<UserDto> GetUserByEmailAsync(string emailAddress, CancellationToken cancellationToken = default){var dbUser = await context.Users.AsNoTracking().FirstOrDefaultAsync(u => u.Email == emailAddress, cancellationToken);// TODO: handle null user if not found.// https://github.com/Northwind/Northwind.UserManagement/issues/324return new UserDto{Id = dbUser.Id,Name = dbUser.Name,Email = dbUser.Email,TenantId = dbUser.TenantId.ToString()}}}✅ Figure: Good example - The `TODO` is tracked on the backlog, so the developers and the Product Owner have visibility of the problem and can plan and prioritise accordingly
Tip: If you are reviewing a Pull Request and you spot a
TODOwithout a link to a PBI, you should either create the PBI and update the code (Good Samaritan) or request the change before approving and merging the code.Do you monitor your application for vulnerabilities?
Efficient software developers don't reinvent the wheel and know the right packages to use when monitoring vulnerabilities in both frontend and backend packages. 🔐 Using a bunch of third-party libraries as the supporting building blocks to build modern, high-quality applications became a common practice since they save time and money in full-stack projects.
But this comes with an unexpected side effect: out-of-date packages that must be updated and re-tested, and even worse, vulnerabilities can be introduced!
One of the big challenges for developers to address is when a project has been delivered to a client and gone into maintenance mode. With no developer actively working on the project, if a vulnerability is discovered in a library referenced in the project, no one will be aware of it, and it will cause pain.
However, if you monitor the packages you have installed, and a vulnerability is reported, then as developers, we have a duty of care to inform our clients.
Level 0 - Manual tracking
List all installed packages in a file and cross-check with the advisory board and Google it, and change each lines regularly. Not recommended because this consumes time.
❌ Figure: Bad example - Tracking list of packages manually
Level 1 - Using tools to scan for vulnerabilities
Modern package managers such as npm or NuGet offers a way to check for vulnerabilities in the installed libraries. See Do you keep your npm and yarn packages up to date?
- npm:
npm audit - yarn:
yarn audit - dotnet cli:
dotnet list package --vulnerable
Regularly running this command can give a summarised report on known vulnerabilities in the referenced libraries.
This is an improvement over manual tracking but still requires a developer to check out the latest code and then run the command.
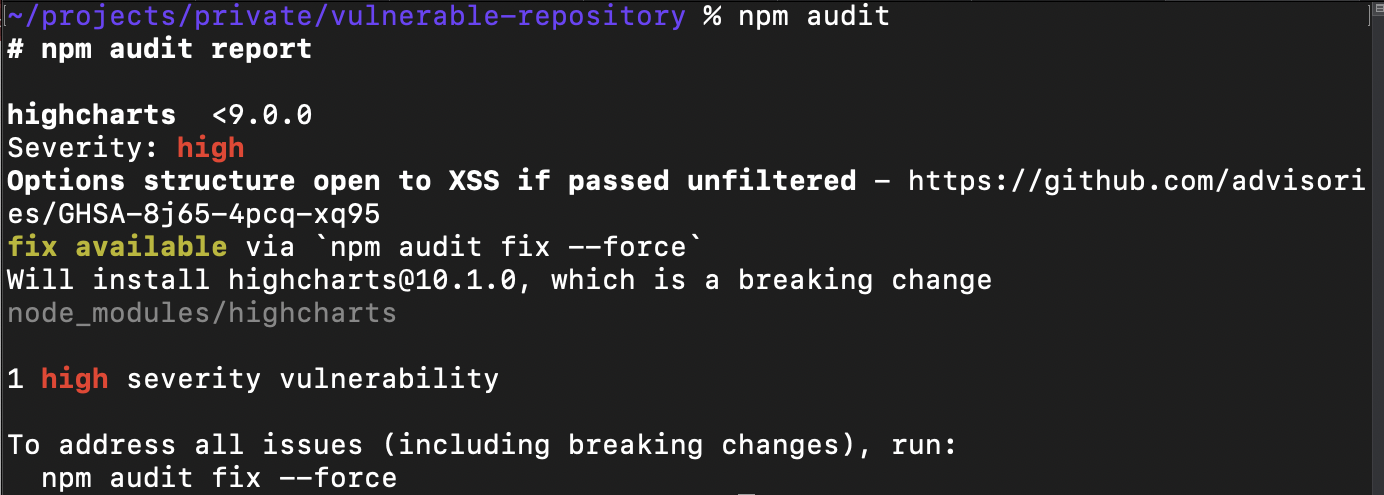
😐 Figure: OK example - This npm audit command informs that there is 1 package with a high severity vulnerability
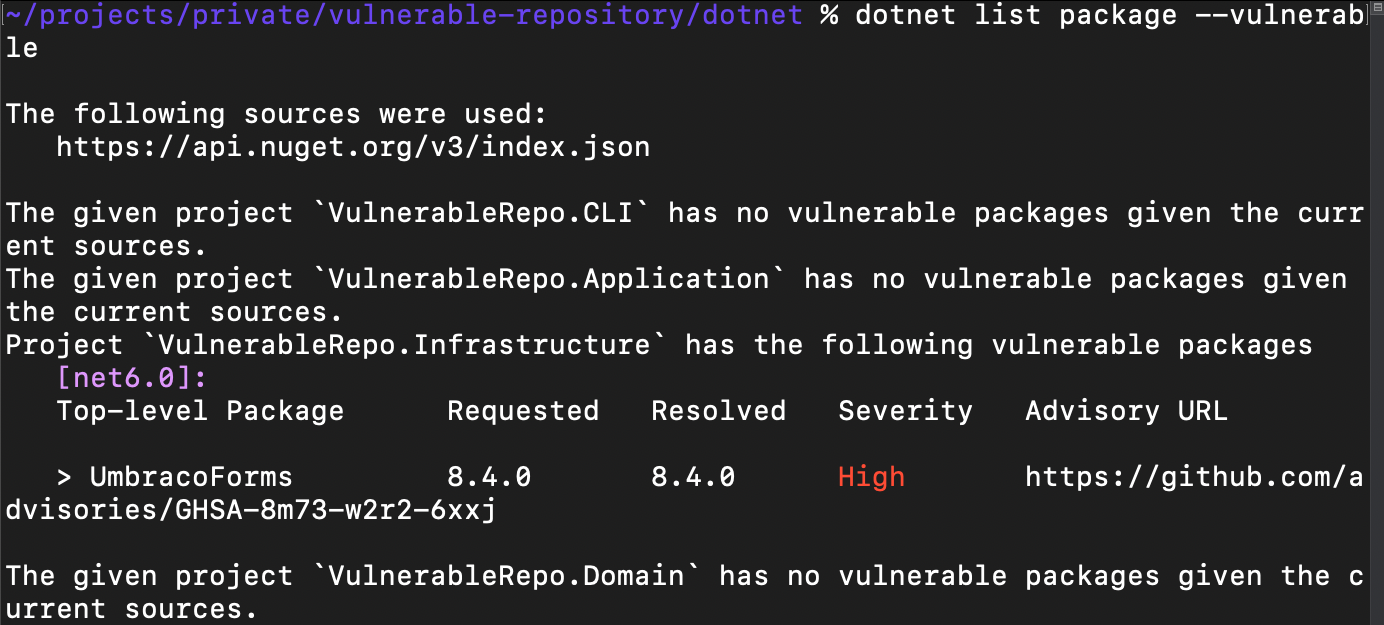
😐 Figure: OK example - This dotnet command informs that there is 1 package with a high severity vulnerability
Level 2 - Automate vulnerability scanning (recommended)
Using 3rd party tools can help you to automate vulnerability scanning.
These tools will alert you whenever there's a security vulnerability detected in the project and optionally raise a PR for it.
Some of the available tools in the market:
- Dependabot - free for all repositories under GitHub, easy to set up in the repository settings (recommended). Used in SSW Rules
- GitHub Enterprise Advanced Security - $ includes Dependabot plus additional features like code scanning. See here for more details.
- Snyk - $
- Sonatype - $
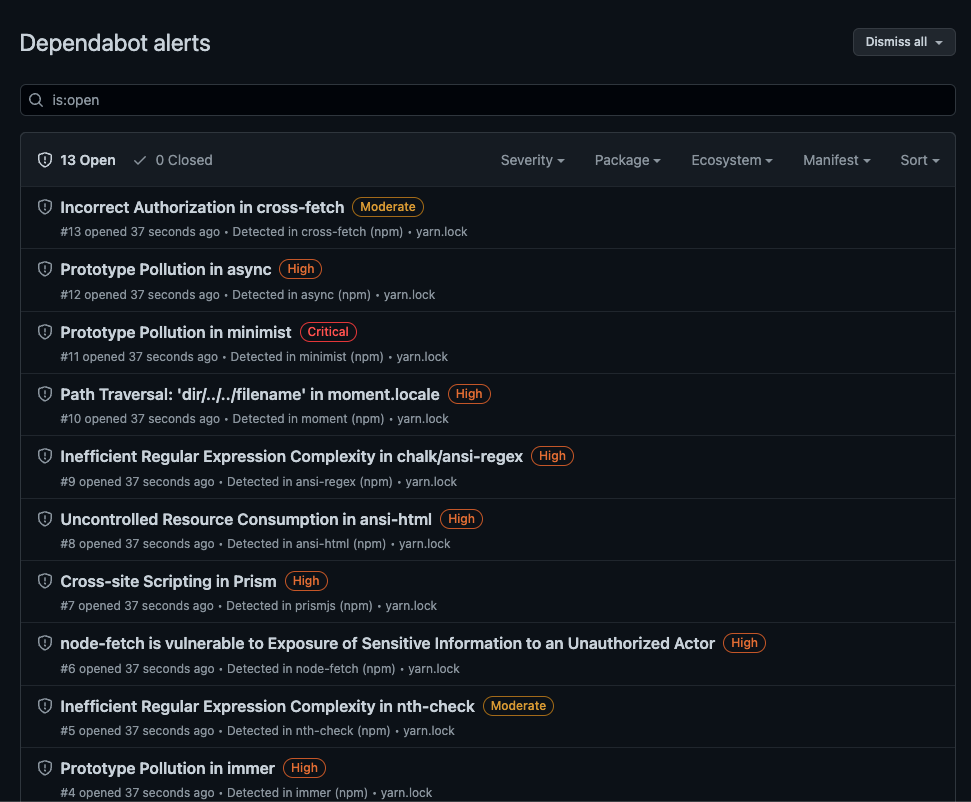
✅ Figure: Good example - Dependabot produces a vulnerability report periodically (and can raise a PR for you)
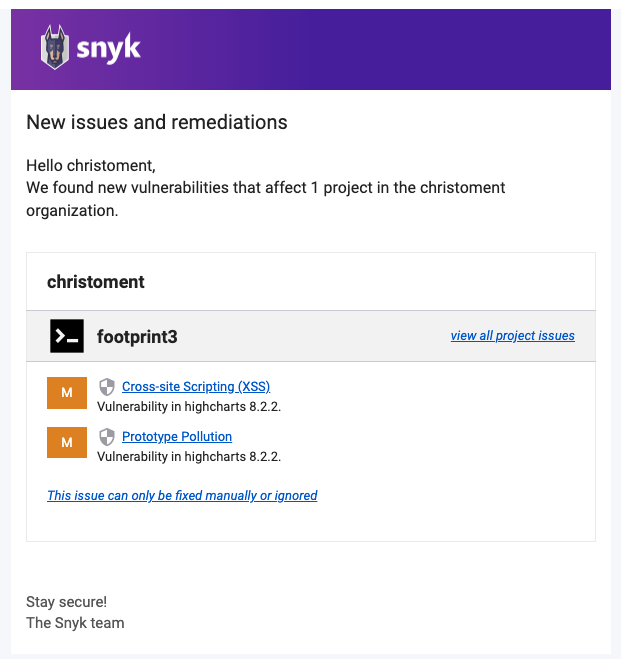
✅ Figure: Good example - Snyk produces a vulnerability detection alert email
Do you keep your code consistent using .editorconfig?
It's important that the code in a project is kept consistent. This is hard to do when you have developers working in different environments.
Using a .editorconfig file is the best way to manage this.
See the EditorConfig file specification
Most IDEs will automatically find and use a .editorconfig file to format code.
See Keep your code clean, automatically!.
✅ Figure: 
❌ Figure: 
Creating .editorconfig files
In VS 2022
- Open the Add New Item dialog (Ctrl+Shift+A)
- Search for "EditorConfig"
- Select a config file depending on your project
Figure: Creating .editorconfig in VS 2022
Manually
- Create a new file called .editorconfig at the root of your project
- Add styling rules based on your needs
Ensuring compliance
To ensure your team is following this standard, you can add it to your Definition of Done.
Additionally, you can have a PR check that enforces .editorconfig rules, but its always better to do this locally.
Learn more on:
Do you know how to read source code?
Recognizing the importance of code reading is fundamental in the realm of programming and software development. Similar to deciphering a language, it unveils the intricacies of software design, logic, and functionality. Beyond writing code, this skill enables efficient troubleshooting, collaboration, and continuous improvement in a dynamic technological landscape.
You need to have the following prerequisites so that you can read the code smoothly afterwards.
- Basic knowledge - Knowledge of relevant languages and underlying technologies
- Software function - You must know what the software does, what features it has, and what configurations it has. You need to read the user manual first, then let the software run, and feel it for yourself
- Relevant documentation - Read the relevant internal documents, Readme or Release Notes, Design or Wiki. These documents can let you understand all aspects of the software. If your software doesn't have documentation, then you can only count on the original author of the software still alive and willing to communicate
- The structure of the code - You need to know what is the function of each directory. If the program you want to read is organized under some standard framework, such as the Clean Architecture. Then congratulations, the code is not difficult to read
Next, you need to understand what parts of the code of this software are made up of. Below is a list for reference.
- Interface/abstract definition - Any code will have many interfaces or abstract definitions, which describe the data structures or business entities that the code needs to deal with and the relationships between them. It is very important to understand these relationships
- Module adhesive layer - A lot of our code is used to glue code, such as middleware, Promises pattern, Callback, proxy and delegation, dependency injection and so on. The gluing techniques between these code modules are very important. Because they will split the code that would otherwise be straightforward, making it difficult for you to understand their relationships
- Business Process - This is how the code runs. In the beginning, we don't want to go into the details. But we need to figure out at a high level what the entire business process looks like. And in this process, how data is passed and processed. Generally speaking, we need to draw program flow charts
- Detailed implementation - After understanding the above three aspects, you will have a general understanding of the framework and logic of the entire code. At this point, you can dive into the details and start reading the code for the specific implementation. In general, you need to know the following facts, which will help you find the key points when reading the code
- Code logic - The code has two kinds of logic. One is business logic. The other is control logic. You need to separate these two kinds of logic. The reason why many code bases are confusing is that these two kinds of logic are mixed
- Error handling - According to the Pareto principle, 20% of the code is normal logic and the other 80% of the code is dealing with various errors. Therefore, when you read the code, you can completely delete or comment out all the error-handling code, which will leave a clean and simple code with normal logic. By eliminating distracting factors, the code can be read more efficiently
- Data processing - As long as you look carefully, you will find that a lot of our code is there to manipulate data. They are long and boring. You can ignore them since they are not the main logic
- Important algorithm - Generally speaking, there will be many important algorithms in our code. It is not necessarily a sorting or search algorithm. But maybe some other core algorithms, such as index table algorithms, globally unique identifier algorithms, information recommendation algorithms, statistical algorithms, etc. These relatively hardcore algorithms can be very hard to read, but they tend to be the most technical parts
- Low-level interaction - Some code interacts with the underlying system, generally with the operating system. Therefore, reading this kind of code usually requires some low-level technical knowledge. Otherwise, it is difficult to read
- Runtime debugging - Most of the time, you don't know what happened unless the code is running. So we let the code run, and then analyse the log or use breakpoints to debug it. Seeing the code in action is a great way to understand it
To sum up, the way to read the code is as follows:
- Generally use a top-down, general to detail reading method called "Peeling the Onion"
- Drawing is necessary. Such as program flow chart, call sequence diagram, module organization diagram, etc
- Categorize code logic and eliminate the noise. So the main logic will be clearer
- Debugging and tracing the code is the best way to understand what's going on in the code's execution
Do you check before installing 3rd party libraries?
Efficient software developers don't reinvent the wheel and know the right libraries to use. Using an existing and well-tested library will speed up development time.
However, there are scenarios where the libraries integrated in a project bring overhead in the future. For example, if a project is using a NuGet package that is no longer being maintained and does not support the latest .NET version. This incompatibility would force the development team to refactor the code to use another library if they wish to use the latest version of .NET.
Looking for the right library can help to minimize the chances of a project hitting these scenarios. Here are some of the common things to check before installing a library:

1. Is it valuable?
Only install libraries that bring big value to the project.
❌ Libraries for trivial functions (e.g.
is-odd- checking if a number is odd or not)❌ Installing multiple libraries with duplicate use-cases (e.g. installing two component libraries Angular Material and NG-ZORRO Ant Design)
✅ One library for one use-case e.g. one for component, one for authentication
✅ Libraries providing complex or standard use cases that have been tested thoroughly e.g. validating credit card numbers, validating email format
2. Is it actively maintained?
The next thing to consider is the library’s lifespan. The last thing that we want is to integrate a library into our project only to find out that next month it will no longer be supported.
Couple of things to check:
✅ High download count – Frequently used libraries are more likely to be supported longer.
✅ Recently updated – Checking the library’s last updated date is a good start to decide whether the library is actively maintained or not.
✅ Good maintainers profile – Libraries sponsored by big companies (e.g. Angular by Google) or established names would be more likely to last longer than a library maintained by an unknown person.
✅ Low GitHub issues count – Many unresolved serious issues may be an indicator that the library is not actively maintained.
❌ Figure: Bad example - Unmaintained library - little to no activity - https://github.com/douglasgsouza/mat-row-keyboard-selection/pulse/monthly
✅ Figure: Good example #1 - Popular npm library with lots of stars and recently updated- https://github.com/date-fns/date-fns
✅ Figure: Good example #2 - Well maintained and active library - https://github.com/date-fns/date-fns/pulse/monthly
3. Is it compatible?
Most libraries are only built for a specific version of a runtime / framework.
e.g. The npm library
@angular/material@14.2.3is only targeted for Angular 14 and NuGet libraryMicrosoft.EntityFrameworkCorev6.0.7only supports .NET 6.It is important to check the compatibility to make sure that the library will work as intended.
Although some libraries can work with older framework versions, it’s a good idea to avoid being in this situation as this could introduce unintended bugs which increase the overhead in debugging your code.
4. Is it high quality?
Next is to dive deep down into the details and check for the quality of the library itself.
Here are things to check:
✅ Maintainer's profile - A high profile maintainer with a good presence in the community or who is doing a lot of contribution provides a good boost of confidence in the library.
✅ Presence of unit tests and good coverages - This improves our confidence that the code will not break across versions
✅ Changelogs and versioning - Good changelogs between releases enable developers to check for any potential breaking changes.
5. Is it an appropriate license?
Not all libraries available on npmjs and NuGet are free to use. The library license can range from free-to-use to paid.
Always check the license associated with the package before deciding to use it in production. You can check common available licenses on choosealicense.com.
❌ Figure: Bad example - npm - uncommon license, need to check for conditions and fees - https://npmjs.com/package/highcharts
❌ Figure: Bad example - NuGet – uncommon license, need to check for conditions and fees - https://nuget.org/packages/PDFTron.NET.x64
✅ Figure: Good example - npm - MIT License, free to use - https://npmjs.com/package/date-fns
✅ Figure: Good example - NuGet – MIT License, free to use - https://nuget.org/packages/Newtonsoft.Json/13.0.1
6. What are the bundle characteristics?
Client-side applications (Angular, React, or Blazor WASM) benefit hugely from reducing the size of the code that a user needs to download (also known as bundles) to run our application.
Installing and using many libraries can increase the size of our application's bundle and slow down these client-side applications. Staying aware of the bundle characteristics and optimising the size where possible can ensure that we keep our application start-up quick.
JavaScript projects
There are tools out there to help us figure out the impact of installing a library on our end bundle size e.g. BundlePhobia or BundleJs
On top of this, we can also check for a library’s tree-shaking capability. Tree-shaking is a process to remove unused code from a library in the final bundle.
Unfortunately, there's no easy way to know if a library is tree-shakable other than to read the documentation and experiment with tools such as BundleJs to see the final bundle size when importing several items from the library.
.NET Projects
Unfortunately, there are no tools available yet to check for bundle size of NuGet packages.
To reduce the final build size, .NET provide a built in feature Trimmer, but these needs to be done carefully as apps that use reflection might not work as expected. Read more about Trimmer.
7. Have you documented the decision?
- Have a 2nd pair of eyes - Lastly before deciding to install the library, check with another developer that is experienced in the scope of your project (e.g. look for a senior JavaScript developer's opinion if the project is an Angular project). Having a 2nd qualified person to agree with your decision is a good indicator that you are picking a good library.
- Document the decision - Always keep track of the reasoning when developers decided to go with a particular library instead of another one. This helps future developers working on a project to maintain the project. Future developers will have better context and will be able to make a better decision should there be any situational or business requirement changes. A package audit log is a great way to record all the decisions.
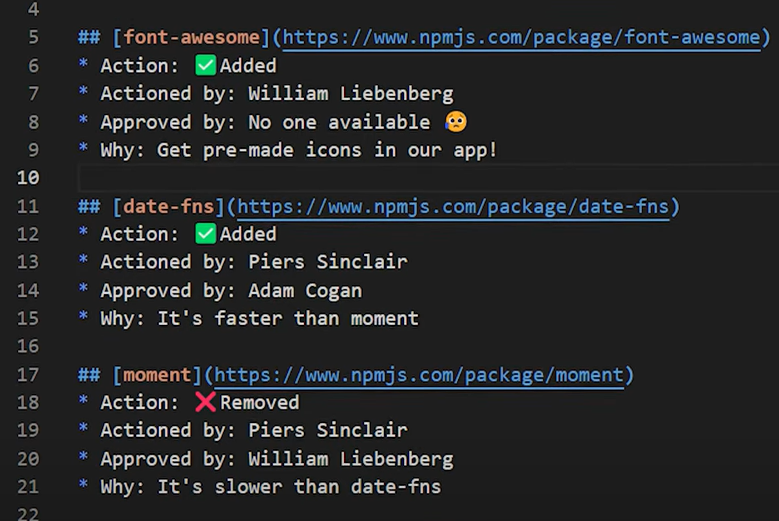
✅ Figure: Good example - A markdown file should include your reasons to assist future developers
Do you keep a package audit log?
<introEmbed body={<> Packages are the lifeblood of any software project. However, if the team is not careful, that lifeblood can turn into a heavy weight dragging the application down. It's too easy for 10 packages to turn into 1,000. That's why it's crucial to maintain a package audit log. </>} />  A package audit log helps developers track why packages are added, who added, and who approved them. ## What to track? There are lots of things that can be tracked in a package audit log. Generally, you want to keep it as simple as possible and contain only information that isn't easy to find elsewhere. For example, bundle size and load time can easily be found on [Bundlephobia](https://bundlephobia.com), so there is no need to track that. Some developers keep track of minimal information such as: * Name * Link to npm/NuGet * Why (the reason this package version was chosen) While others keep track of maximum information such as: * Name * Link to npm/NuGet * Action (aka "added" or "removed") * Actioned by * Approved by * Why (the reason this package version was chosen) If you go with the maximum information, this smells like Technical Debt. However, it does provide an easy way to find out where the package is, who was involved in adding or removing it and why the change was made. ## Options for Tracking Packages Managing NPM packages is a difficult task, especially when some packages require a certain version to work with the rest of your project or were added for a specific reason. There are 4 different options that you could take: * Option 1 - Log the information in Technologies-and-Architecture.md * Option 2 - Make good commit messages * Option 3 - Leave comments in package.json * Option 4 - Option 2 and sometimes Option 3 (✅ Recommended) ### Option 1 - Log the information in Technologies-and-Architecture.md Markdown provides an easy way to format package log information, so one way of storing it is in Technologies-and-Architecture.md Alternatively, you could keep track of this information in a different file for each project in the solution. e.g `\FrontendPackageAuditLog.md` or `\BackendPackageAuditLog.md` Pros and Cons: ✅ More descriptive notes about the package ❌ Hard to keep up-to-date ❌ Tech Debt It's imperative that the package audit log is updated every time a package is added or removed. So, add it to the Sprint Review as an item to action every week. That way, the team is aware of all changes, and any missed changes are caught. This process could be taken even further by having automated checks in PRs to add package details and then generating release notes based on those PRs. <asideEmbed variant="greybox" body={<> ## Project Northwind Frontend (React) These are all the packages that have been added to the project (ordered by most recent). **Note:** Statistics like load time and bundle size can easily be found at [Bundlephobia](https://bundlephobia.com/) ### [font-awesome](https://www.npmjs.com/package/font-awesome) * Action: ✅ Added * Actioned by: William Liebenberg * Approved by: No one available 😥 * Why: Get pre-made icons in our app! ### [date-fns](https://www.npmjs.com/package/date-fns) * Action: ✅ Added * Actioned by: Piers Sinclair * Approved by: Adam Cogan * Why: It's faster than moment ### [moment](https://www.npmjs.com/package/moment) * Action: ❌ Removed * Actioned by: Piers Sinclair * Approved by: William Liebenberg * Why: It's slower than date-fns ### [bootstrap](https://www.npmjs.com/package/bootstrap) * Action: ✅ Added * Actioned by: Brady Stroud * Approved by: Piers Sinclair * Why: For pretty styling on the application </>} figureEmbed={{ preset: "default", figure: 'XXX', shouldDisplay: false }} /> <figureEmbed figureEmbed={{ preset: "badExample", figure: 'Figure: Bad example - Packages documented in Technologies-and-Architecture.md', shouldDisplay: true } } /> ### Option 2 - Make good commit messages Commit messages are an easy way for devs to add information about package updates/changes without the need to go out of their way. So putting your package audit information into your commit messages is another option for storing it. Pros and Cons: ✅ Easy for the dev ❌ Message could be overwritten by a more recent commit ❌ Not as easy to read (have to hover over it to read) <figureEmbed figureEmbed={{ preset: "okExample", figure: '<imageEmbed alt="Image" size="large" showBorder={false} figureEmbed={{ preset: "default", figure: \'OK example - Using the VS Code extension GitLens, can see commits on hover within the code\', shouldDisplay: true }} src="/uploads/rules/package-audit-log/screen-shot-2022-12-15-at-09.33.31.png" />', shouldDisplay: true } } /> ### Option 3 - Leave comments in package.json Having comments in package.json is an efficient way of getting important package information across to other developers without the need for them to go to other files. Pros and Cons: ✅ More descriptive notes about the package ✅ Notes are documented together with the package ❌ Can cause noise and clutter within package.json <figureEmbed figureEmbed={{ preset: "okExample", figure: '<imageEmbed alt="Image" size="large" showBorder={false} figureEmbed={{ preset: "default", figure: \'OK example - Packages documented within package.json\', shouldDisplay: true }} src="/uploads/rules/package-audit-log/screen-shot-2022-12-16-at-09.19.32.png" />', shouldDisplay: true } } /> ### Option 4 - Option 2 and sometimes Option 3 (✅ Recommended) Creating commit messages and leaving comments in package.json both have their advantages but neither is perfect. By combining the two you can get the best of both worlds. Leave a good commit message for every package change so that a developer can investigate it further and if there's something abnormal about the package then leave a comment so it's immediately clear to other developers. Pros and Cons: ✅ Low Tech Debt ✅ Easy for the dev ✅ Descriptive for the packages that require it ❌ Not as easy to read (sometimes required to read into the commits) <figureEmbed figureEmbed={{ preset: "goodExample", figure: '<imageEmbed alt="Image" size="large" showBorder={false} figureEmbed={{ preset: "default", figure: \'Both Git commits with GitLens and package.json comments\', shouldDisplay: true }} src="/uploads/rules/package-audit-log/screen-shot-2022-12-16-at-09.21.30.png" />', shouldDisplay: true } } />Do you use package managers appropriately?
Advice like this can be a minefield, and is constantly in flux, but there are some rules-of-thumb that can make life simpler.

Figure: Default ASP.NET Core project is package management done wrong
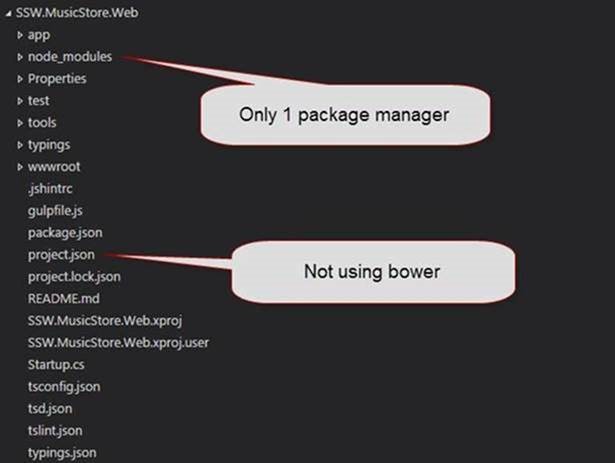
Figure: Project using good package management
Bower is dead

Figure: Bower is dead
File-New Project in Visual Studio comes with bower packages, and there are a lot of old blog posts that recommend bower for client side libraries, but bower is dead. Angular2 is discouraging its use, and npm has all the same packages, and more. Prefer npm over bower, even for client-side dependencies.
Use a single package manager
For client side libraries, avoid mixing npm, jspm and manually copy/pasted files. Life will be simpler if you stick with just 1.
Right now, this is npm, but watch out for jspm, which shows a lot of promise if you can get past the steep learning curve.
Be careful with versioning
Theoretically, everything in npm is using semantic versioning. In practice, people aren’t that diligent, so it pays to be careful with your version numbers. It’s not rare for versions to disappear from npm, or for a build-servers internet connection to be flaky. If these issues are happening, consider using npm-shrinkwrap to lockdown dependency versions.
Track your dev dependencies and dependencies separately
All package managers distinguish between those used for development, and those used for the application. Use this feature – it will save you time.
Do you know the best package manager for Node?
When working with Node.js, choosing the right package manager can significantly impact your project's performance, consistency, and ease of use. While npm is the default, developers often seek alternatives like Yarn, Bun, or pnpm for various advantages. But which one should you use?
1. pnpm (Recommended ✅)
::: img-medium
 :::
:::- Efficient Disk Space Usage: pnpm uses a content-addressable file system to store all files in a single place on the disk. This means multiple projects can share the same packages, reducing disk space usage
- Fast and Reliable: With pnpm, package installations are faster because it avoids duplicating files in
node_modules. Instead, it creates hard links, which makes the process quicker and more efficient - Strict Dependency Management: pnpm enforces stricter rules for dependency resolution. Unlike npm and Yarn, pnpm prevents "phantom dependencies," ensuring that your project is more predictable and less prone to errors
2. npm
::: img-medium
 :::
:::npm is the default package manager bundled with Node.js. It is straightforward to use and integrates seamlessly with the Node ecosystem.
Notable Incident: In 2016, the removal of the "left-pad" package from npm caused widespread issues, making developers reconsider their reliance on the platform.
Pros:
- Comes pre-installed with Node.js, so no additional setup is needed
- Vast package registry with millions of packages
Cons:
- Slower compared to pnpm and Yarn
- Issues with dependency resolution and "phantom dependencies."
3. Yarn
::: img-medium
 :::
:::Yarn was developed by Facebook to address some of npm's shortcomings, such as speed and reliability.
Pros:
- Faster than npm, especially with the offline cache feature
- Better dependency management and deterministic builds with Yarn's
yarn.lockfile
Cons:
- Slightly more complex to configure compared to npm
- Still not as space-efficient as pnpm
4. Bun
::: img-medium
 :::
:::Bun is a newer entrant that aims to be an all-in-one tool for Node.js, combining package management with a fast JavaScript runtime and bundler.
Pros:
- Extremely fast, built from the ground up in Zig, a systems programming language
- Includes built-in support for TypeScript and JSX, making it attractive for modern web development
Cons:
- Relatively new and less mature than the other options
- Smaller community and less extensive documentation
While npm, Yarn, and Bun each have their strengths, pnpm is the recommended package manager for most Node.js projects. Its efficient use of disk space, faster installations, and stricter dependency management make it a superior choice. However, the best package manager for you may depend on your specific project's needs and your team's preferences.
Do you use local copies to resolve race condition?
Code that looks perfectly fine in a single-threaded scenario could be vulnerable to race condition when some value is shared among multiple threads.
Examine the following if-statement:
if (A is null || (A.PropertyA == SOME_CONSTANT && B)){// some logic}❌ Figure: Figure: Bad example - Vulnerable to race condition
When the above code is run single-threaded, the second part of the if-condition would never be reached when A is null. However, if A is shared among multiple threads, the value of A could change from not null to null after passing the first check of if-condition, resulting in a NRE in the second check of if-condition.
In order to make the code thread-safe, you should make a local copy of the shared value so that value change caused by another thread would no longer lead to crash.
var copyA = A?.PropertyA;if (A is null || (copyA == SOME_CONSTANT && B)){// some logic}✅ Figure: Figure: Good example - Local copy to resolve race condition
C# Code - Do you use primary constructors to keep your code clean?
When following best practices and using dependency injection, you will often find yourself with a class that has a lot of properties that are only set once, in the constructor. This can lead to a lot of boilerplate code that is not needed. C#12 introduces Primary Constructors, which allow you to define the constructor and the properties in one place.
public class Hero{public Hero(string name, string power, string city){_name = name;_power = power;_city = city;}private readonly string _name;private readonly string _power;private readonly string _city;public override string ToString() => $"{_name} has {_power} and lives in {_city}";}❌ Figure: Figure: Bad example - large amount of boiler plate code needed to store injected properties.
public class Hero(string name, string power, string city){public override string ToString() => $"{name} has {power} and lives in {city}";}✅ Figure: Figure: Good example - using Primary Constructors to reduce boilerplate code.
In the example above we the
Heroclass has access to the parameters passed into the Primary Constructor so we don't need to store them in private fields. We can use them directly in theToString()method.For more information on Primary Constructors see learn.microsoft.com/en-us/dotnet/csharp/whats-new/tutorials/primary-constructors
C# Code - Do you use collection expressions to keep your code clean?
Do you know collection expressions can make your code cleaner? They can be used to create arrays, lists, and other collections in a single line of code.
var numbers1 = new List<int> {1, 2, 3, 4, 5};❌ Figure: Figure: Bad example - Verbose way of constructing a list
var numbers2 = new[] { 1, 2, 3, 4, 5 };😐 Figure: Figure: OK example - using implicit arrays
List<int> numbers3 = [1, 2, 3, 4, 5];✅ Figure: Figure: Good example - using collection expressions
Another advantage of collection expressions is that they can be passed into methods accepting different types of list collections. The compiler is smart enough to determine the correct underlying type.
Foo([1,2,3]);Foo2([1,2,3]);Foo3([1,2,3]);void Foo(IEnumerable<int> numbers){// Do work}void Foo2(List<int> numbers){// Do work}void Foo3(int[] numbers){// Do work}Figure: Versatile use of collection expressions in methods with varying collection types
For more information on collection expressions see here: learn.microsoft.com/en-us/dotnet/csharp/language-reference/operators/collection-expressions
Reading Source Code - Do you understand the importance of interfaces and abstract classes?
When embarking on understanding a new codebase, it's crucial to identify the components that offer the most insight with the least effort. Interfaces and Abstract Classes stand out as the pillars that uphold the structure and behavior of the code, providing a clear overview without delving into the intricate details of implementation.
Video: How to Read Source Code: Interfaces and abstract classes | Luke Mao | SSW Rules (6 min)Why interfaces and abstract classes are important
Interfaces and abstract classes provide 2 main insights by helping you know:
- Data structures and their relationships
- What functionality a class can provide
What is an interface?
An interface defines properties and methods that a class must implement. It only provides the method signatures without any implementation details.
Imagine we have objects of different shapes, such as circles and rectangles. Each shape can have its own color. Also, all shapes have an area that can be calculated. However, the calculation changes depending on the type of shape. For example, a circle calculates area using PI and radius, while a rectangle uses the width and height.
So, we can define an interface called
Shape:interface Shape {color: string;area(): number;}It declares a property called color and a method called area. The specific implementation will be inside the
CircleandRectangleclass.Circle class
class Circle implements Shape {color: string;radius: number;constructor(color: string, radius: number) {this.color = color;this.radius = radius;}area(): number {return Math.PI * this.radius * this.radius;}}Rectangle class
class Rectangle implements Shape {color: string;width: number;height: number;constructor(color: string, width: number, height: number) {this.color = color;this.width = width;this.height = height;}area(): number {return this.width * this.height;}}These implementations can then be instantiated separately depending on the kind of shape that is needed.
const circle = new Circle("red", 10);console.log(circle.color); // outputs "red"console.log(circle.area()); // outputs "314.1592653589793"const rectangle = new Rectangle("blue", 5, 10);console.log(rectangle.color); // outputs "blue"console.log(rectangle.area()); // outputs "50"Its important to note that you can get interfaces wrong. For example you could not use interfaces or you could over use interfaces
interface Animal {eat(): void;}interface Mammal extends Animal {breathe(): void;}interface Dog extends Mammal {bark(): void;}interface Bulldog extends Dog {snore(): void;}❌ Figure: Figure: Bad Example - When you over abstract, it becomes harder to find the right place to add new methods
The role of the interface is to reduce coupling. For example, if you need to change how the area is calculated for a rectangle but not for a circle, you can do so without affecting how the circle behaves. It also improves scalability. Every time a new shape is added, there is already a set of well-defined methods, making it easier to add the new class.
Interfaces are contracts that dictate what a class can do without specifying how it does it. They are crucial in defining behavior and ensuring consistency across different implementations.
What is an abstract class?
An abstract class is a class that cannot be instantiated and serves as a blueprint for creating derived classes. It's similar to an interface but allows you to provide fully implemented methods, not just method declarations. A class that uses an abstract class is known as a concrete class.
Imagine various payment methods, such as bank transfer and credit card payment.
We can define an abstract class called Payment:
abstract class Payment {amount: number;constructor(amount: number) {this.amount = amount;}abstract processPayment(): void;receipt(): void {console.log(`Payment of $${this.amount} has been processed.`);}}It's similar to an interface. It defines a property called
amountand a method calledprocessPayment.processPaymentwill change depending on the payment method. There is also areceiptmethod, and unlike theprocessPaymentmethod, it should be the same for all kinds of payment methods. Thisreceiptmethod can be directly implemented in an abstract class but not in an interface.This abstract class would then be used to define different types of payments, such as Bank Transfer or Credit Card Payment:
Bank Transfer class
class BankTransfer extends Payment {processPayment(): void {console.log(`Processing a bank transfer of $${this.amount}`);}}Credit Card Payment class
class CreditCardPayment extends Payment {processPayment(): void {console.log(`Processing a credit card payment of $${this.amount}`);}}These implementations can then be instantiated separately depending on the kind of payment that is needed.
const bankTransfer = new BankTransfer(512);bankTransfer.processPayment(); // Processing a bank transfer of $512bankTransfer.receipt(); // Payment of $512 has been processed.const creditCardPayment = new CreditCardPayment(1024);creditCardPayment.processPayment(); // Processing a credit card payment of $1024creditCardPayment.receipt(); // Payment of $1024 has been processed.The primary purpose of abstract classes is to solve code reuse problems. If we don't use a Payment abstract class here, the
BankTransferandCreditCardPaymentclasses will have duplicate receipt methods.When to focus on interfaces and abstract classes
The best time to read interfaces and abstract classes is:
- After understanding the business problem
- Before diving into implementation details
Other Benefits
There more benefits to using interfaces and abstract classes such as in Unit Testing which you can read here
Conclusion
Knowing when and how to read interfaces and abstract classes streamlines your learning process and equips you with a framework to understand the broader system architecture and its components.
Do you use "var"?
In C# the "var" keyword can be used instead of providing an explicit type when declaring a variable. The type is then inferred from the initial assignment of the variable.
It is just a short hand to save developers from typing out the type of a variable.
List<string> items = new List<string>();❌ Figure: Figure: Bad example - You should just use "var" instead of "List<string>"
var item = new List<string>();✅ Figure: Figure: Good example - Using "var" to save a few keystrokes and reduce repetition
This can be kept consistent by creating an editorconfig file which can then generate compile time warnings.
An example editor config, look for the var preferences.
Code - Do you handle all possible scenarios?
When developers build software, they naturally become experts in using the software. This is problematic because with this expertise, they will tend to focus on the happy path of the user. However, it is important to consider all possible scenarios that could occur. This includes edge cases, such as invalid inputs, unexpected user behavior, and system failures. By handling all possible scenarios, you can ensure that your code is robust and reliable.
Here are some tips to help you spot where you need to handle more scenarios:
- Think of potential "unhappy paths"
- Ask yourself "what could the user do wrong here?" (e.g. What if the user enters an invalid email address?)
- Assume your users are doing something for the first time
- Get a test please on all your code
- Do some exploratory testing
❌ Figure: Bad example - Users can enter invalid emails
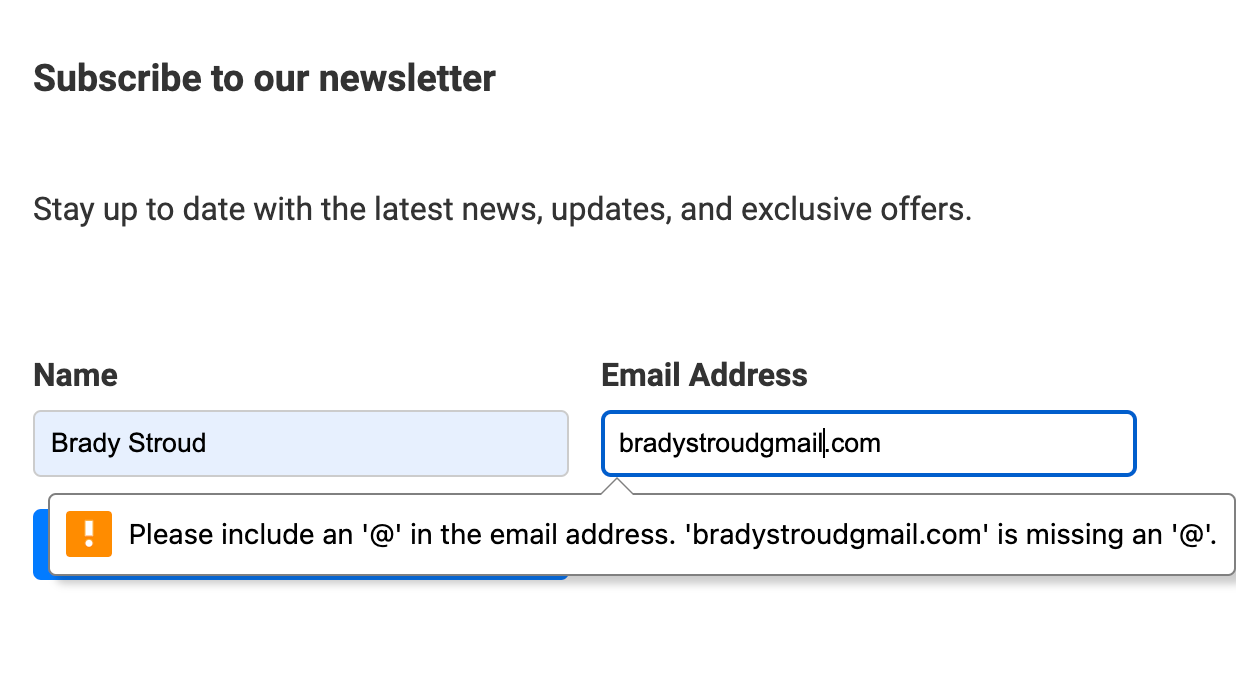
✅ Figure: Good example - Code checks the email is valid
Do you know how to get code line metrics?
When working on software projects, it’s important to keep track of your codebase's size and structure. Code line metrics help you understand the scope of the code, identify potential areas for refactoring, and maintain a healthy balance between files, blank line comments, and code. Without these metrics, your project can become difficult to manage, and you may struggle to track progress or maintain code quality.
Using cloc to measure code line metrics
The tool cloc is a straightforward yet powerful way to count the number of files, blank lines, comment lines, and physical lines of source code across various programming languages. Here’s how you can use it effectively:

✅ Figure: Good example - Running cloc on EagleEye project
Understand the output
- File Count: The number of files in your project. Helps you understand the size and complexity
- Blank Lines: These can indicate the organization of your code. Provides insights into the readability
- Comment Lines: The number of lines that contain comments. Helps you gauge how well-documented the code is
- Physical Lines of Code (LOC): Counts the actual code lines, excluding blank lines and comments
✅ Benefits of tracking code metrics
Tracking code metrics with cloc helps in maintaining clean and well-documented code. It provides insights that can lead to:
- Improved code quality: By identifying parts of the code that are poorly documented or unnecessarily complex
- Better project management: Enabling project leads to assess the size and complexity of the codebase and plan accordingly
- Code review efficiency: Assisting in identifying files that have changed significantly and might require more thorough reviews
By integrating cloc into your workflow, you can ensure that your codebase remains manageable, maintainable, and well-documented as your project evolves.
Do you know how to use single codebase for multiple domains with TinaCMS and Next.js?
Using multiple domains using TinaCMS and Next.js requires few steps. This setup is particularly useful for managing content across different locations or websites, all from a centralized codebase. We will cover how to structure your project, configure middleware for domain-specific content, and manage environment variables for different locations.
Project Structure
We will detail a project structure using a simple example of a cooking application. We are using the App Router introduced with version 13.4 of Next.js.
To support multiple domains, the project structure is organized as follows:
1. Content Directory
The content for each location is organized under the
contentdirectory, which contains various subdirectories for recipies, posts, and pages. Each location, such as Australia or France, has its own subdirectory underpagesandrecipeswhich contains the content relevant to that location.├── content| ├── pages│ │ ├── Australia│ │ ├── France│ ├── posts│ └── recipes│ ├── Australia│ └── France2. Application Directory
The src/app/[location] directory contains the shared codebase for all locations. This includes components like the posts, recipes, and other custom pages. The
layout.tsxandpage.tsxfiles handle the layout and page rendering for each location.├── src│ ├── app│ │ ├── [location]| | | ├── [filename]│ │ │ | ├── page.tsx| │ │ ├── layout.tsx| │ │ ├── not-found.tsx| | | ├── page.tsx│ │ │ ├── posts| | | ├── recipesMiddleware Configuration
To handle domain-specific routing, we use a middleware file
middleware.tslocated in the src directory. This middleware rewrites URLs based on the hostname, routing requests to the appropriate location's content.Middleware Implementation
import { NextResponse } from 'next/server';import type { NextRequest } from 'next/server';/*** Middleware function to handle URL rewriting based on the request's hostname.** This middleware dynamically rewrites incoming requests to ensure that* content is served according to the domain (hostname) being accessed.** - For local development, it redirects requests to a default location.* - For production, it matches the domain to a location and rewrites the URL* accordingly.** @param {NextRequest} request - The incoming HTTP request object.* @returns {NextResponse} - The response object with the rewritten URL.*/export function middleware(request: NextRequest) {// Retrieve the hostname from the request headersconst hostname = request.headers.get('host');// Extract the pathname from the requested URL (e.g., /about, /contact)const { pathname } = request.nextUrl;// Check if the request is coming from a local development environmentconst isLocal =hostname?.includes('localhost') || hostname?.includes('127.0.0.1');// Variable to store the response after applying the rewrite ruleslet nextResponse;// Retrieve the list of locations and corresponding domains from environment variablesconst locationsList = process.env.NEXT_PUBLIC_LOCATION_LIST? JSON.parse(process.env.NEXT_PUBLIC_LOCATION_LIST): [];// If running locally, rewrite the URL to include the default locationif (isLocal) {nextResponse = NextResponse.rewrite(new URL(`/${process.env.DEFAULT_LOCALHOST_LOCATION}${pathname}`,request.url));} else {// Loop through the list of locations to find a matching domainfor (const location of locationsList) {if (hostname == location.domain) {// Rewrite the URL to the corresponding location's contentnextResponse = NextResponse.rewrite(new URL(`/${location.location}${pathname}`, request.url));break; // Exit the loop once a match is found}}}// Return the response with the rewritten URLreturn nextResponse;}/*** Configuration object for the middleware.** Specifies the paths that should be handled by the middleware. The matcher* excludes certain paths (e.g., Next.js internals, static files, favicon)* to avoid unnecessary processing.*/export const config = {matcher: [/** Match all request paths except for the ones starting with:* - _next (Next.js internals like static files and scripts)* - static (static assets like images or stylesheets)* - favicon.ico (the site's favicon)* - Files with extensions (e.g., .js, .css, .png)*/'/((?!api|_next|static|favicon.ico|.*\\..*).*)',],};Environment Variables and Vercel Configuration (or other host)
You need to configure the following environment variables for the middleware to function correctly:
- NEXT_PUBLIC_LOCATION_LIST: A JSON string representing the list of locations and their corresponding domains.
- DEFAULT_LOCALHOST_LOCATION: The default location to use when running the application locally.
Example of
.envfile:NEXT_PUBLIC_LOCATION_LIST='[{"location": "australia", "domain": "website-australia.com.au"}, {"location": "france", "domain": "website-france.fr"}]'DEFAULT_LOCALHOST_LOCATION="australia"If deploying on Vercel, ensure that the environment variables are set up in the project settings under Environment Variables. This will allow Vercel to use these variables during the build and runtime.